
Prater & Borden
W 2014 roku osiemnastoletnia Brisha Borden została oskarżona o popełnienie kradzieży mienia wartości osiemdziesięciu dolarów po tym, jak postanowiła przejechać się pozostawionym i niezabezpieczonym rowerkiem dziecięcym. Brisha w przeszłości, w wieku nieletnim, popełniła mniejsze wykroczenia.
Rok wcześniej czterdziestojednoletni Vernon Prater został przyłapany na kradzieży narzędzi ze sklepu o łącznej wartości 86,35 dolarów. Vernon był już oskarżony o kradzież z bronią w ręku, za co dostał wyrok pięciu lat pozbawienia wolności. Był też oskarżony o próbę dokonania napadu z bronią w ręku.
W USA w tamtym czasie używany był system służący predykcji ryzyka, który miał na celu ocenę, czy dana osoba w przyszłości będzie popełniać inne przestępstwa. System ten dawał ocenę od 1 do 10, gdzie im wyższa wartość liczbowa, tym większe ryzyko popełniania przestępstw w przyszłości. Borden – czarna nastolatka – dostała ocenę wysokiego ryzyka: 8. Prater zaś – biały, dorosły mężczyzna – ocenę niskiego ryzyka: 3. Po dwóch latach Brisha Borden nie popełniła żadnego przestępstwa, natomiast Vernon Prater odsiadywał wyrok ośmiu lat pozbawienia wolności po tym, jak włamał się do magazynu i ukradł elektronikę wartości kilku tysięcy dolarów. [1]
Ukryte dane
Zautomatyzowane systemy uczenia maszynowego i big data są coraz liczniejsze w naszym codziennym życiu. Poczynając od algorytmów proponujących użytkownikowi serial do obejrzenia, kończąc na takim, który zadecyduje o racie twojego kredytu hipotecznego. I właśnie, w momencie, kiedy algorytm decyduje o tak ważnej dla człowieka sprawie wchodzimy na dość niebezpieczny grunt. Czy możemy w ogóle ufać takim systemom, aby podejmowały istotne decyzje? Algorytmy komputerowe dają poczucie bezstronności i obiektywności. Czy jednak istotnie tak jest?
W dużym skrócie – algorytmy uczenia maszynowego „uczą się” podejmować decyzje na podstawie dostarczonych danych. Niezależnie od sposobu tej nauki, czy to proste drzewa decyzyjne, czy bardziej zaawansowane sztuczne sieci neuronowe, z założenia algorytm powinien wyciągnąć ukryte w danych wzorce. Tak więc algorytm będzie tak obiektywny, jak obiektywne są dane uczące. O ile możemy się zgodzić, że na przykład dane medyczne czy pogodowe są obiektywne, ponieważ oczekiwane rezultaty nie wynikają z decyzji ludzkich, o tyle decyzje o np. przyznaniu kredytu czy zatrudnieniu były historycznie podejmowane przez ludzi. A ludzie, jak wiadomo, nie są stuprocentowo obiektywni i kierują się określonym światopoglądem i niestety też uprzedzeniami. A te uprzedzenia trafiają do danych w mniej lub bardziej bezpośredni sposób.
Kwestia przygotowania danych nadających się do trenowania algorytmów uczenia maszynowego to bardzo obszerne zagadnienie. Omówienie możliwych rozwiązań to temat na osobny artykuł.
W takim razie, skoro nie chcemy aby algorytm podejmował decyzje na podstawie płci, wieku czy koloru skóry, to czy nie można po prostu nie podawać tych danych? Takie naiwne podejście, choć wydaje się logiczne, ma jedną dużą lukę. Informacja o tych danych wrażliwych może być (i prawdopodobnie jest) zakodowana w innych, pozornie niepowiązanych informacjach.
Dane historyczne są tworzone przez ludzi, a ludzie niestety kierują się pewnymi uprzedzeniami. Decyzje te przesiąkają przez dane, i nawet jeśli tworząc model uwzględni się, aby na wejściu nie uwzględniał danych o rasie, wieku, płci itp. to może się okazać, że informacje te przedostają się pośrednio poprzez np. informacje o kodzie pocztowym. Można przykładowo użyć sieci Bayesowskich (Bayesian networks) do zwizualizowania wzajemnych połączeń między różnymi cechami. To narzędzie ma na celu wskazanie gdzie mogą ukryte być dane, na podstawie których nie chcielibyśmy podejmować decyzji. [2]
Sądowy system oceny ryzyka w USA
Powróćmy do algorytmu wykorzystywanego w systemie karnym USA (system COMPAS). Julia Dressel i Hany Farid [3] spróbowali zbadać działanie tego systemu. Na początku przeprowadzili sondę, w której ankietowani bez żadnego doświadczenia w kryminologii dostali krótki opis dokonanego przestępstwa osoby oskarżonej (w tym jej wiek i płeć, ale nie rasę) i historię jej wcześniejszych oskarżeń, ich celem było przewidzenie, czy dana osoba będzie ponownie karana w ciągu najbliższych dwóch lat. Wyniki przeprowadzonego badania wykazały skuteczność (67%) podobną do systemu wykorzystywanego przez system karny USA (65,2%). Co ciekawe, udział odpowiedzi fałszywie pozytywnych, czyli takich, w których osoby oskarżone zostały przydzielone błędnie do grupy wysokiego ryzyka, był stały bez względu na rasę. Osoby czarnoskóre, zarówno w anonimowej sondzie, jak i według systemu COMPAS, miały większe prawdopodobieństwo bycia zakwalifikowanymi do grupy wyższego ryzyka niż osoby białe. Dla przypomnienia – ankietowani nie posiadali informacji o rasie osób oskarżonych.
Następnie przetestowane zostały inne metody uczenia maszynowego, w tym algorytm regresji logistycznej z dwoma cechami na wejściu – wiek i liczba wcześniejszych oskarżeń. Algorytm ten działa w taki sposób, że na (w tym przypadku) dwuwymiarowej płaszczyźnie (każda oś jest wartością danej cechy) umieszczane są poszczególne pomiary ze zbioru treningowego. Następnie wyznaczana jest prosta oddzielająca przypadki z dwóch różnych kategorii. Zwykle nie jest możliwe idealne wyznaczenie prostej, która by bezbłędnie oddzielała dwie kategorie. Dlatego też wyznacza się prostą, której błąd jest minimalny. W ten sposób uzyskano takie działanie prostej, która dzieli płaszczyznę na dwie kategorie – osoby które w przeciągu dwóch lat zostały oskarżone, i te które nie zostały oskarżone (Rys.1).
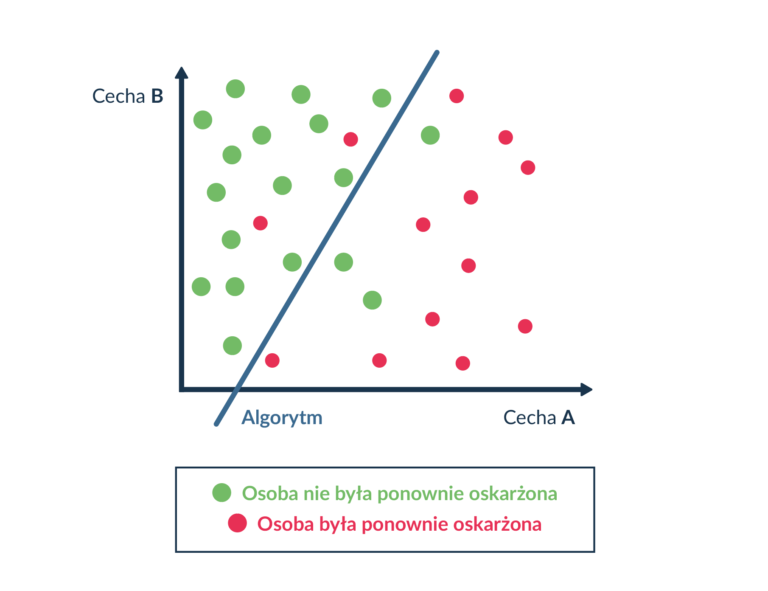
Algorytm ten ma skuteczność (66,8%) zbliżoną do systemu COMPAS (65,4%). W tym przypadku również zaobserwowano dużo wyższy odsetek osób czarnych niepoprawnie sklasyfikowanych jako osoby wyższego ryzyka od osób białych.
Jak się okazuje, informacja o rasie może przeniknąć też w danych o ilości zatrzymań [2][3]. Na przykład w USA osoby czarnoskóre są aresztowane za posiadanie narkotyków cztery razy częściej od osób białych [8][9].
Niedziałające modele
Czasami modele po prostu nie działają.
W 2012 roku opublikowano dane systemu oceniającego nowojorskich nauczycieli z lat 2007-2010. System ten dawał nauczycielom ocenę od 1 do 100 rzekomo na podstawie osiągnięć uczniów danego nauczyciela. Gary Rubinstein [4] postanowił przyjrzeć się opublikowanym danym. Zauważył, że w statystykach nauczyciele, którzy zostali objęci programem oceny przez kilka lat, mają osobną ocenę z każdego roku. Wychodząc z założenia, że ocena nauczyciela nie powinna się dramatycznie zmienić z roku na rok, postanowił sprawdzić jak zmieniła się w rzeczywistości. Wykreślił oceny nauczycieli, gdzie na osi X oznaczył ocenę z nauczania pierwszego roku, a na osi Y ocenę z drugiego roku nauczania tej samej klasy. Każda kropka na wykresie reprezentuje jednego nauczyciela (Rys.2).
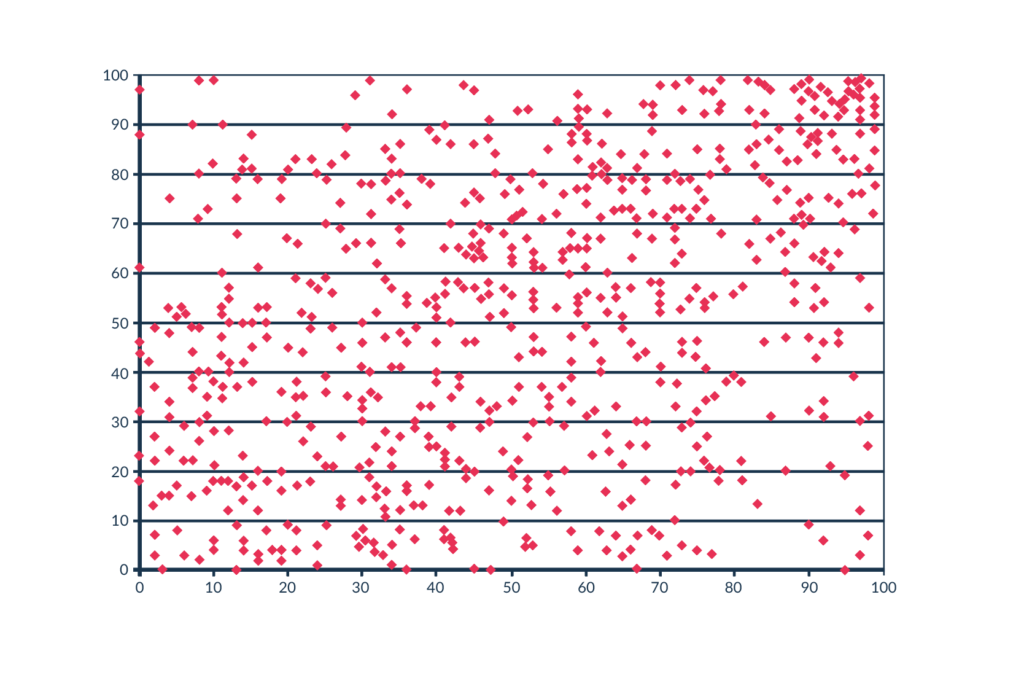
Logicznym wynikiem byłaby zależność zbliżona do liniowej, bądź inna korelacja, ze względu na to że wyniki tej samej klasy u jednego nauczyciela z roku na rok nie powinien się drastycznie zmienić. Tutaj wykres przypomina bardziej generator liczb losowych, a niektóre klasy oceniane na ocenę bliską 100, następnego roku miały wynik bliski 0 i vice versa. Nie jest to wynik, który powinien zwracać system, na podstawie którego ustalane są płace nauczycieli, czy nawet decyzja czy zwolnić taką osobę. Ponieważ ten system po prostu nie działa.
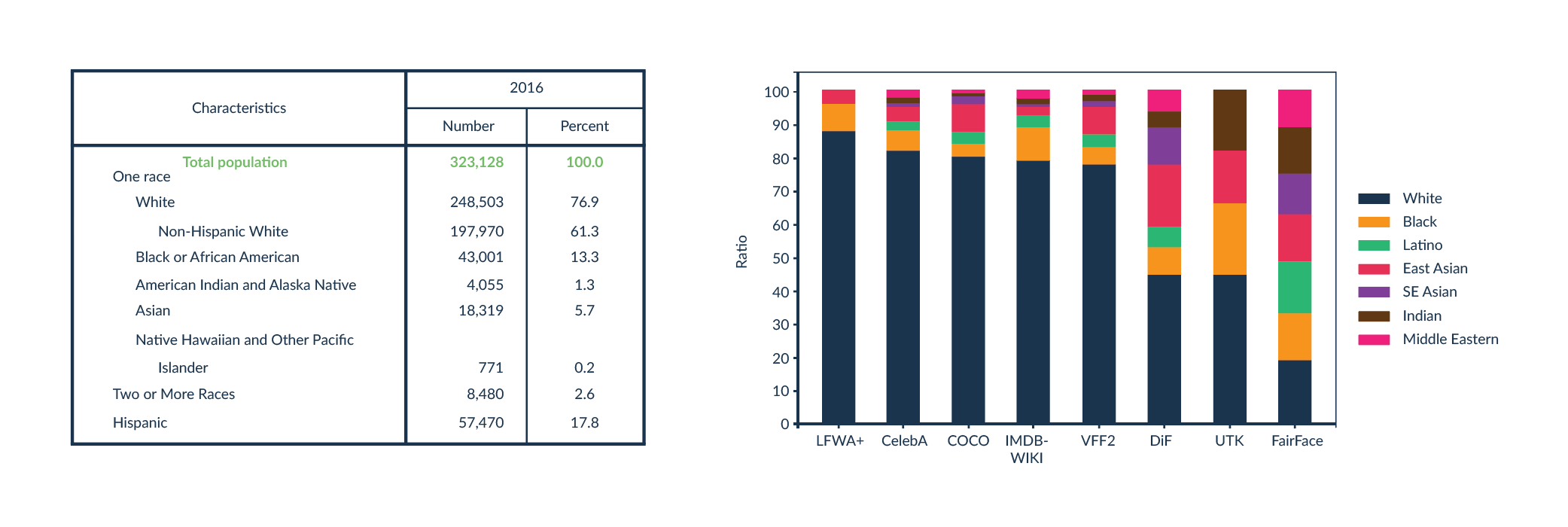
Podobny problem mają algorytmy rozpoznawania twarzy. Zwykle takie technologie są tworzone w taki sposób, że algorytm uczenia maszynowego analizuje wiele obrazów, które są twarzą, i wiele obrazów które przedstawiają coś innego. System wykrywa wzorce, które są charakterystyczne dla twarzy, które nie występują na innych obrazach. Problem zaczyna się, gdy ktoś ma twarz odbiegającą od tych występujących w zbiorze treningowym. Osoby tworzące taki algorytm powinny postarać się o jak najbardziej różnorodny zbiór treningowy. Niestety okazuje się, że często w zbiorach treningowych jest niedostateczna reprezentacja osób o ciemniejszym kolorze skóry. Zbiory treningowe najczęściej mają dystrybucję koloru skóry podobną do społeczeństwa, z którego są zbierane dane. To znaczy, jeżeli zbiór treningowy składa się na przykład ze zdjęć obywateli USA i Europy, wtedy procentowy udział każdego koloru skóry w zbiorze danych będzie zbliżony do tego w demografii USA i Europy, gdzie przeważają osoby o jasnej karnacji (Rys.3).
Na uniwersytecie MIT [5] zbadano dokładność algorytmów rozpoznawania twarzy z uwzględnieniem podziału na płeć i kolor skóry. Okazało się, że technologie najpopularniejszych firm, takich jak Amazon czy IBM, nie radzą sobie z rozpoznawaniem kobiet o ciemnym kolorze skóry (rys.4). W sytuacji, gdy technologie te używane są w produktach wykorzystujących technologię rozpoznawania twarzy, pojawia się problem dostępności i bezpieczeństwa. Jeśli dokładność działania jest niska nawet dla jednej określonej grupy odbiorców, istnieje duże ryzyko uzyskania dostępu do np. telefonu przez osobę do tego nieupoważnioną. W czasach kiedy technologie rozpoznawania twarzy wykorzystywane są przez policję w kamerach monitoringu, istnieje duże ryzyko, że niewinne osoby zostaną błędnie rozpoznane jako osoby poszukiwane. Takie sytuacje już miały wielokrotnie miejsce. A wszystko przez niepoprawnie działający algorytm, który dość łatwo można by naprawić poprzez odpowiednie dobranie danych uczących.
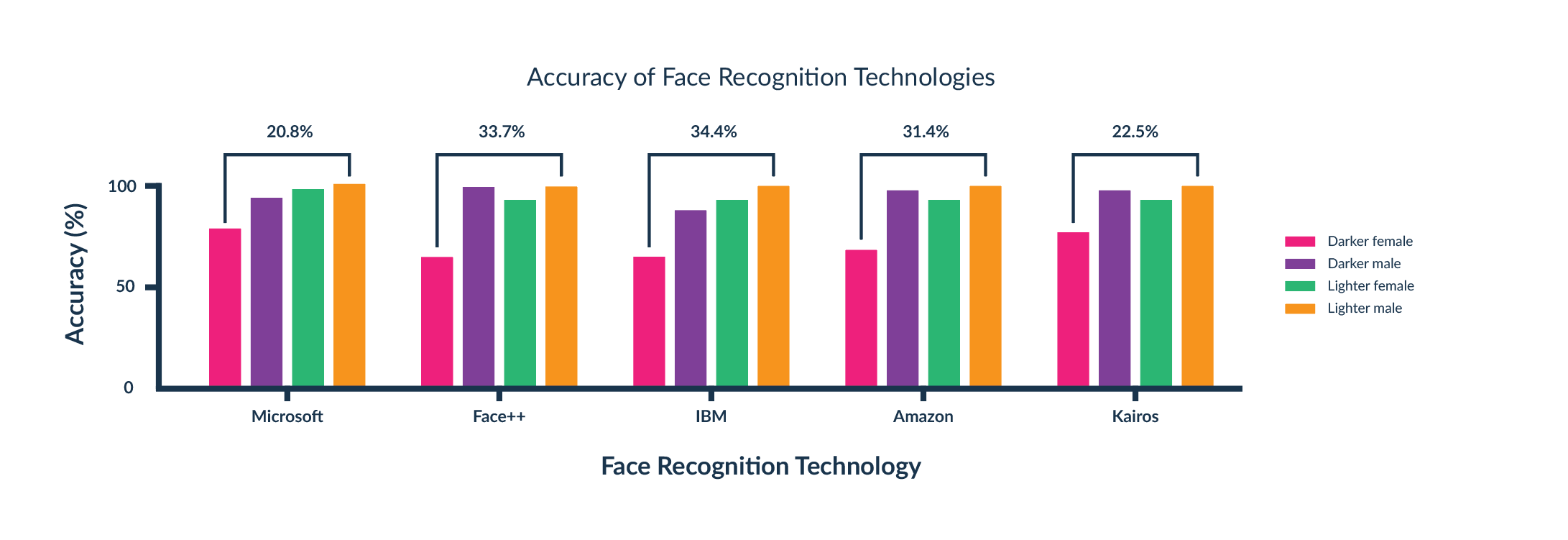
Po opublikowaniu badania MIT większość firm poprawiła działanie swoich algorytmów, dzięki czemu dysproporcje w rozpoznawaniu twarzy są znikome.
Inkluzywny kod
Nie możemy być w stu procentach ufni algorytmom uczenia maszynowego i big data. Zwłaszcza jeśli w grę wchodzi decydowanie o ludzkim losie.
Jeśli chcemy tworzyć narzędzia, które są skuteczne, i nie uczą się uprzedzeń ludzkich, należy zejść do poziomu danych. Trzeba analizować wzajemne zależności atrybutów, które mogą wskazywać na rasę, płeć, czy wiek. Selekcjonować te, które są naprawdę niezbędne do poprawnego działania algorytmu. Następnie konieczna jest analiza samego działania algorytmu i jego wyników, aby zapewnić, że algorytm jest w istocie obiektywny.
Modele uczenia maszynowego uczą się poszukując wzorców i odtwarzając je. Jeśli podajemy nieprzefiltrowane dane historyczne, nie tworzymy tak naprawdę nowych, skuteczniejszych narzędzi, tylko automatyzujemy status quo. A gdy w grę wchodzi ludzki los, my, jako developerzy, nie możemy pozwolić sobie na powtarzanie starych błędów.
Bibliografia
[1] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[2] https://arxiv.org/pdf/2110.00530.pdf
[3] J. Dressel, H. Farid, “The accuracy, fairness, and limit of predicting recidivism”
[4] https://garyrubinstein.wordpress.com/2012/02/26/analyzing-released-nyc-value-added-data-part-1/
[5] https://sitn.hms.harvard.edu/flash/2020/racial-discrimination-in-face-recognition-technology/
[6] https://www.census.gov/content/dam/Census/library/publications/2020/demo/p25-1144.pdf
[7] Kimmo K ̈arkk ̈ainen, Jungseock Joo, “FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation”
[8] https://www.aclu.org/report/tale-two-countries-racially-targeted-arrests-era-marijuana-reform?eType=EmailBlastContent&eId=f3aa6ff4-fdc5-4596-b96a-2c0fe443df39