
Artificial intelligence elevates the capabilities of the machines closer to human-like level at an increasing rate. Since it is an issue of great interest, many fields of science have taken a big leap forward in recent years.
One of the goals of artificial intelligence is to enable machines to observe the world around them in a human-like way. This is possible through the application of neural networks. Neural networks are mathematical structures that, at their base, are inspired by the natural neurons found in the human nerves and brain.
Surely you have felt the presence of neural networks in everyday life many times, for example in:
- face detection and recognition in smartphone photos,
- recognition of voice commands by the virtual assistant,
- autonomous cars.
The potential of neural networks is enormous. The examples listed above represent merely a fraction of current applications. They are, however, related to a special class of neural networks, called convolutional neural networks, CNNs, or ConvNet (Convolutional Neural Networks).
Image processing and neural networks
To explain the idea of convolutional neural networks, we will focus on their most common application – image processing. A CNN is an algorithm that can take an input image and classify it according to predefined categories (e.g. the breed of dog). This is be achieved by assigning weights to different shapes, structures, objects.
Convolutional networks, through training, are able to learn which specific features of an image help to classify it. Their advantage over standard deep networks is that they are more proficient at detecting intricate relationships between images. This is possible thanks to the use of filters that examine the relationship between adjacent pixels.

Each image is a matrix of values, the number of which is proportionate to its width and height in pixels. For RGB images, the image is characterised by three primary colours, so each pixel is represented by three values. ConvNet’s task is to reduce the size of the image to a lighter form. However, it happens without losing valuable features, i.e. those that carry information crucial for classification.
CNN has two key layers. The first one is convolutional layer.
Convulational layer
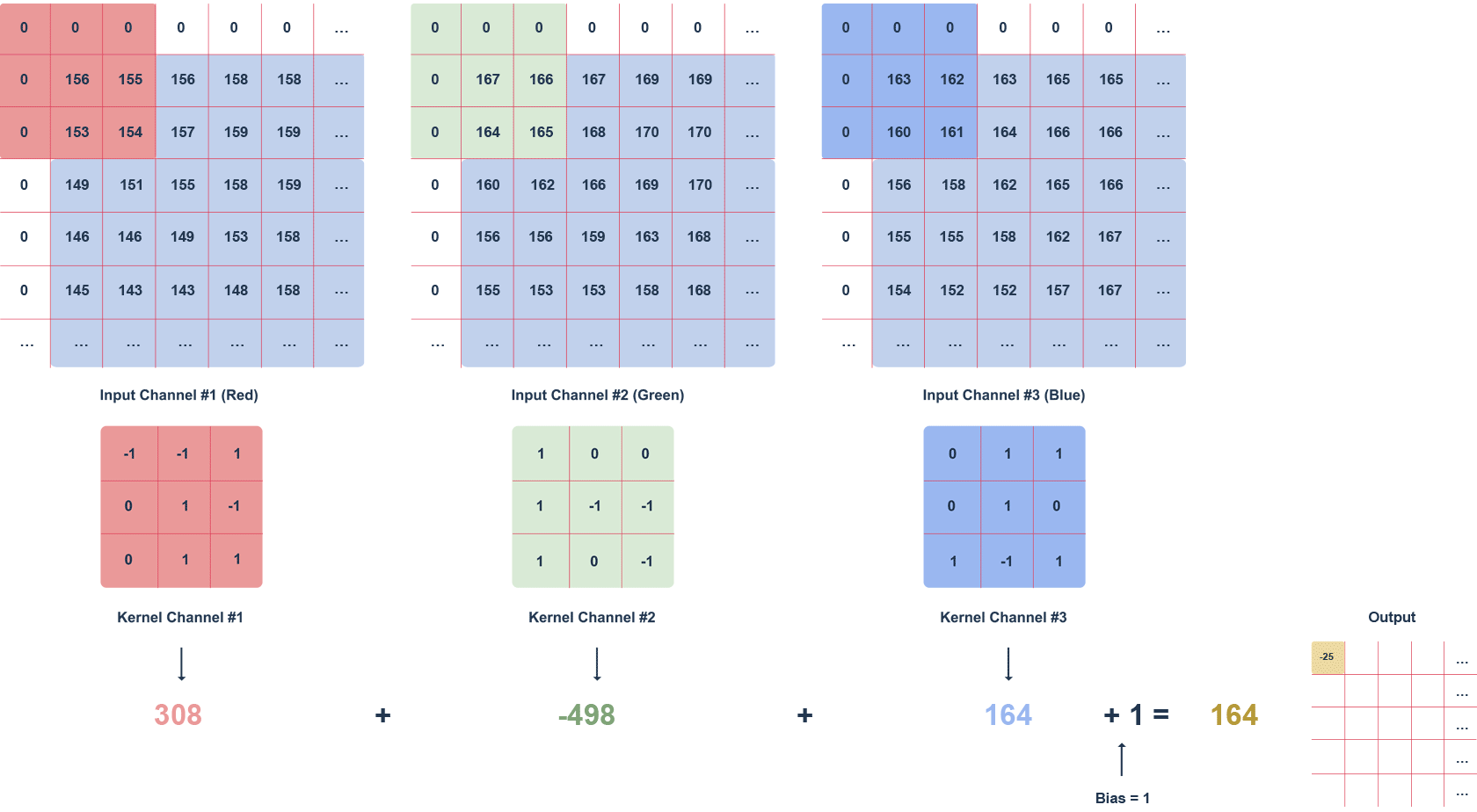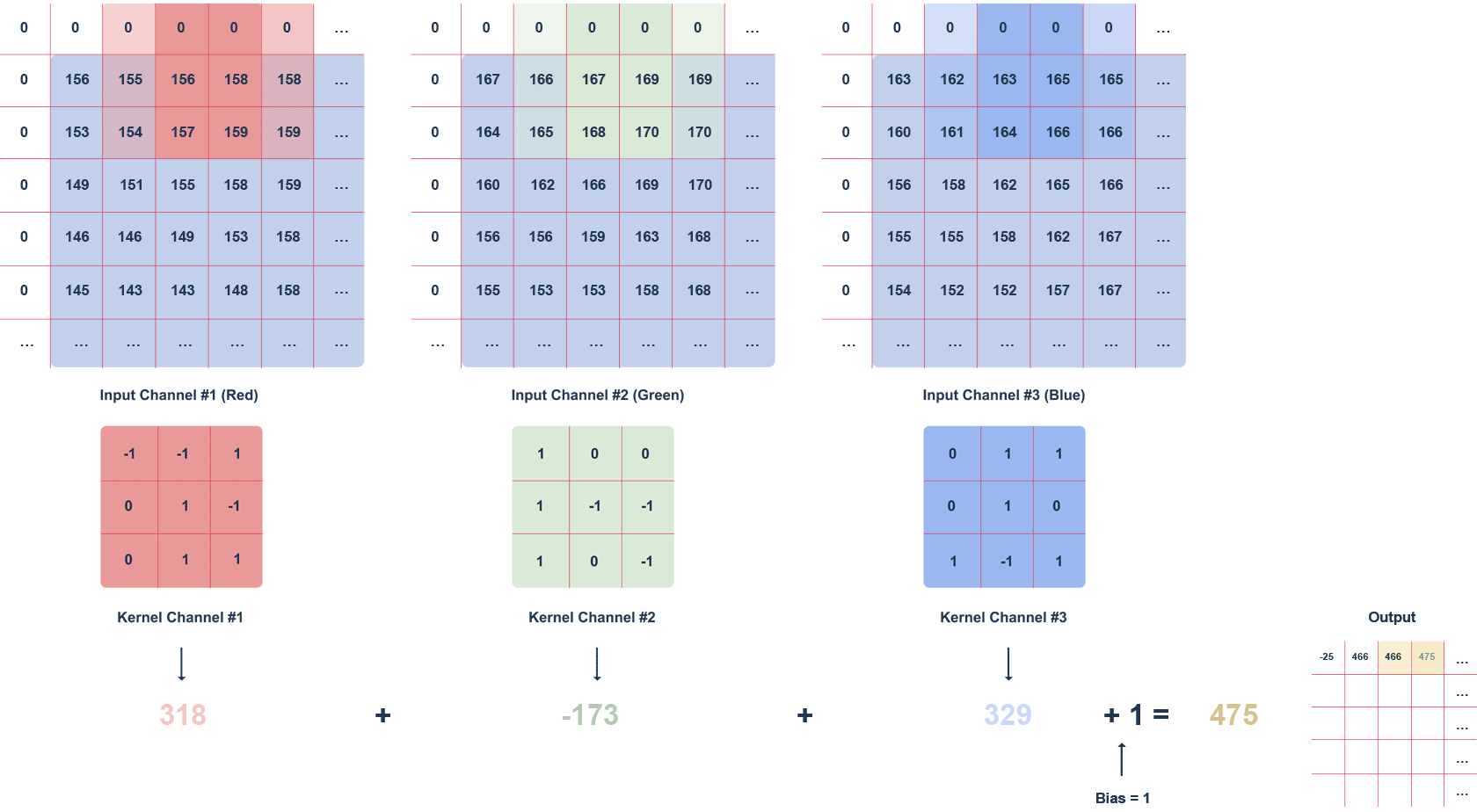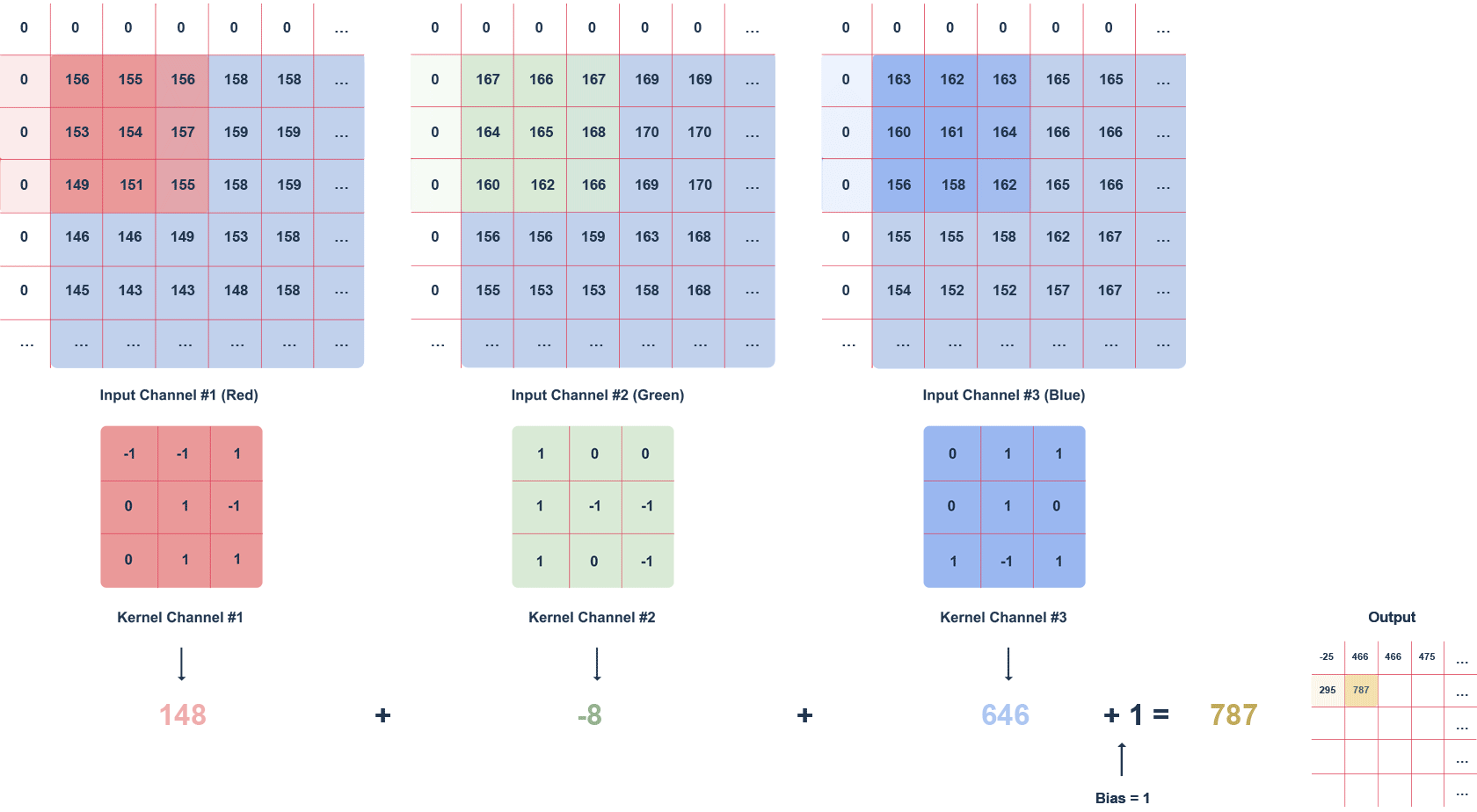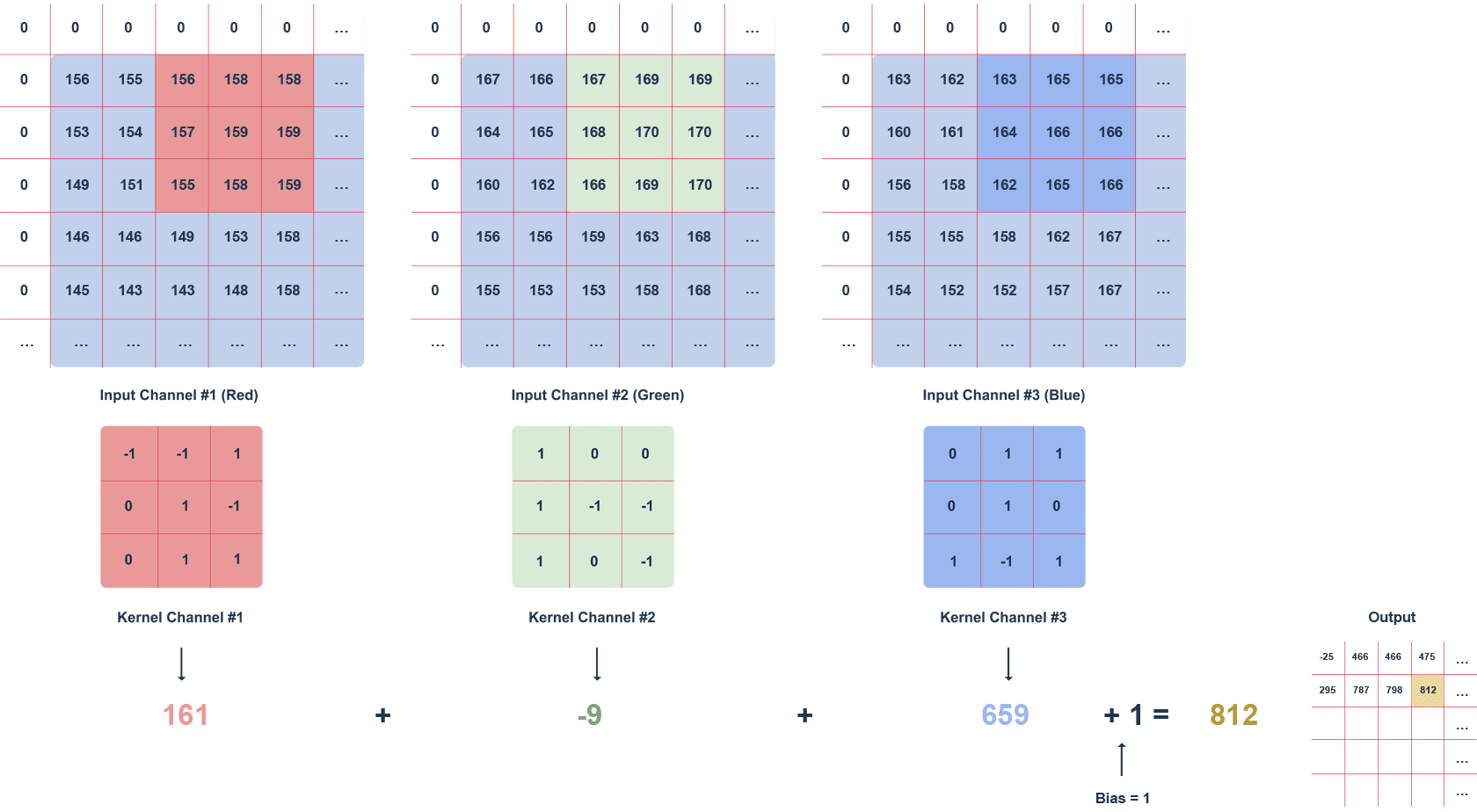
The animation above shows an RGB image and a 3x3x3 filter moving through it with a defined step. The step is the value in pixels by which the filter moves. We can apply the “zero padding” option, i.e. filling with zeros (white squares). This procedure helps preserve more information at the expense of efficiency.
Subsequent values of the output matrix are calculated as follows:
- multiplying the values in a given section of the image by the filter (after the elements),
- summing up the calculated values for a given channel,
- summing up the values for each channel taking into account the bias (in this case equal to 1).
It is worth noting that the filter values for a particular channel may differ. The task of the convolution layer, is to extract features such as edges, colours, gradients. Subsequent layers of the network – using what the previous layers have determined – can detect increasingly complex shapes. Much like the layers of an ordinary network, the convolution layer is followed by an activation layer (usually a ReLU function), introducing non-linearity into the network.
We can interpret the result of the convolution with each filter as an image. Many such images formed by convolution with multiple filters are multi-channel images. An RGB image is something very similar – it consists of 3 channels, one for each colour. The output of the convolution layer, however, does not consist of colours per se, but certain “colour-shapes” that each filter represents. This is also responsible for noise reduction. The most popular method is “max pooling”.
Typically multiple filters are used, so that the convolution layer increases the depth, i.e. the number of image channels.
Bonding layer
Another layer, called the bonding layer, has the task of reducing the remaining dimensions of the image (width and height), while retaining key information needed, e.g. for image classification.

The merging operation is similar to the one applied in the convolution layer. A filter and step are defined. The subsequent values of the output matrix are the maximum value covered by the filter.
Together, these layers form a single layer of the convolutional network. Once the selected number of layers has been applied, the resulting matrix is “flattened out” to a single dimension. It means that the width and height dimensions are gradually replaced by a depth dimension. The result of the convolutional layers translates directly into the input to the next network layers, usually the standard fully connected ones (Dense Layers). This allows the algorithm to learn the non-linear relationships between the features determined by the convolution layers.
The last layer of the network is the Soft-Max layer. It makes it possible to obtain values for the probabilities of class membership (for example, the probability that there is a cat in the image). During training, these are compared with the desired classification result in the applied cost function. Then, through a back-propagation algorithm, the network adjusts its weights to minimise the error.
Convolutional neural networks are an important part of the machine learning development. They contribute to the progress of automation and help extend to human perceptual abilities. Their capabilities will continue to grow with the computing power of computers and the amount of available data.
References
[1] https://medium.com/@raycad.seedotech/convolutional-neural-network-cnn-8d1908c010ab





