
Sztuczna inteligencja w coraz większym tempie przybliża możliwości maszyn do ludzkich. Duże zainteresowanie zagadnieniem sprawia, że w ostatnich latach wiele dziedzin nauki zaliczyło duży skok rozwojowy.
Jednym z celów sztucznej inteligencji jest umożliwienie maszynom obserwowania otaczającego je świata w sposób podobny do ludzkiego. Jest to możliwe poprzez zastosowanie sieci neuronowych. Sieci neuronowe to matematyczne struktury, które w swojej podstawie inspirują się naturalnymi neuronami znajdującymi się w nerwach i mózgu człowieka.
Z pewnością wielokrotnie doświadczyłeś obecności sieci neuronowych w życiu codziennym, przykładowo w:
- wykrywaniu i rozpoznawaniu twarzy na zdjęciach w smartfonie,
- rozpoznawaniu komend głosowych przez wirtualnego asystenta,
- autonomicznych samochodach.
Potencjał sieci neuronowych jest ogromny. Wymienione wyżej przykłady stanowią zaledwie ułamek obecnych zastosowań. Są one jednak związane ze szczególną klasą sieci neuronowych, zwanych konwolucyjnymi, CNN, bądź ConvNet (Convolutional Neural Networks).
Przetwarzanie obrazu a sieci neuronowe
Aby przybliżyć zagadnienie konwolucyjnych sieci neuronowych, skoncentrujemy się na ich najczęstszym zastosowaniu, czyli przetwarzaniu obrazu. CNN to algorytm, który może pobrać obraz wejściowy i sklasyfikować go wedle predefiniowanych kategorii (np. rasy psa). Jest to możliwe dzięki przypisaniu wag różnym kształtom, strukturom, obiektom.
Sieci konwolucyjne poprzez trening są w stanie nauczyć się, jakie cechy szczególne obrazu pomagają w jego klasyfikacji. Ich przewagą nad standardowymi sieciami głębokimi jest większa skuteczność w wykrywaniu zawiłych zależności w obrazach. Jest to możliwe dzięki zastosowaniu filtrów badających zależności pomiędzy sąsiednimi pikselami.

Każdy obraz jest macierzą wartości, których liczba jest proporcjonalna do jego szerokości i wysokości w pikselach. W przypadku obrazów RGB obraz cechują trzy kolory podstawowe, więc każdy piksel reprezentują trzy wartości. Zadaniem ConvNet jest redukcja rozmiaru obrazu do lżejszej formy bez utraty wartościowych cech, czyli tych, które niosą informacje kluczowe dla klasyfikacji.
CNN złożona jest z dwóch kluczowych warstw. Pierwszą z nich jest warstwa konwolucyjna.
Warstwa konwolucyjna
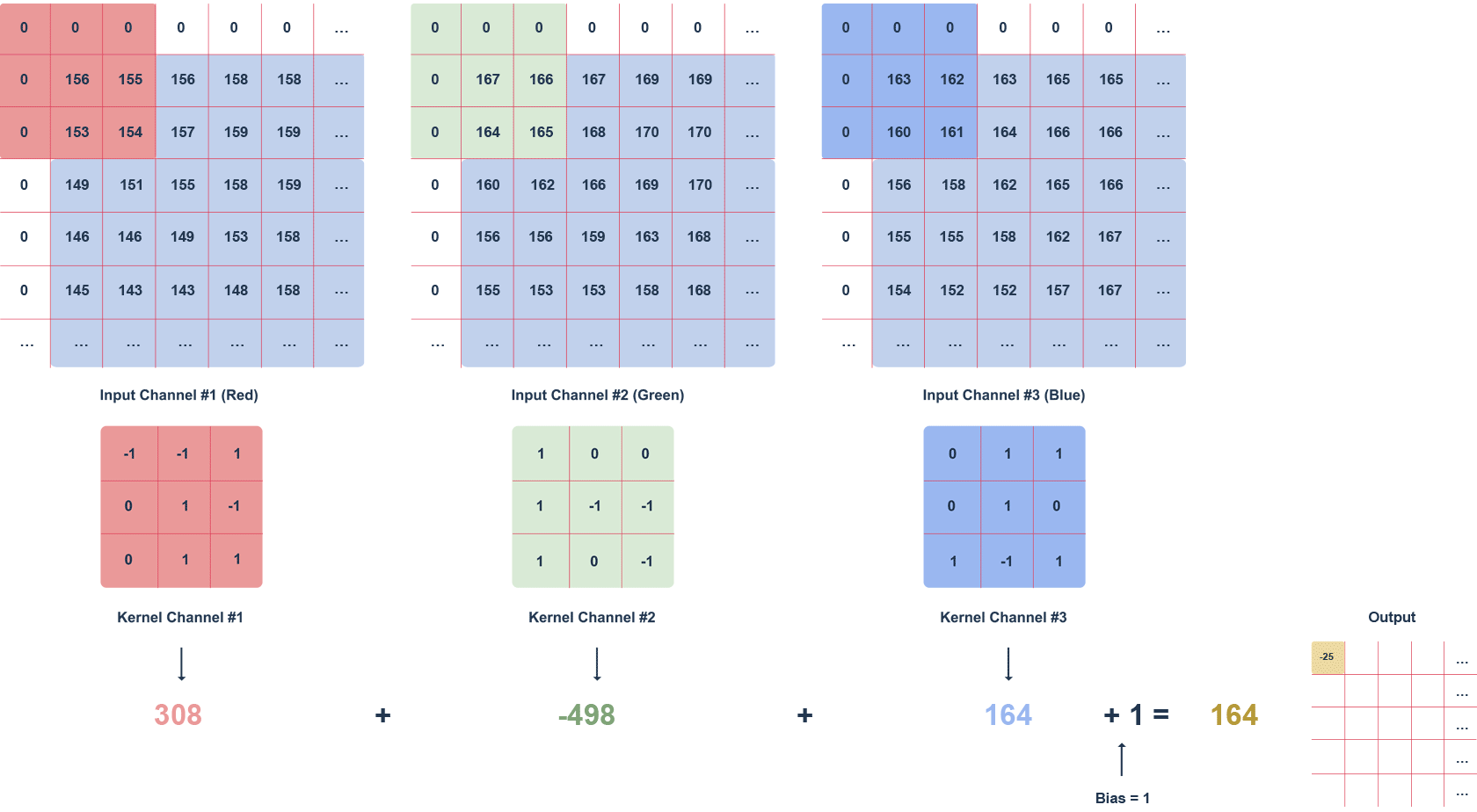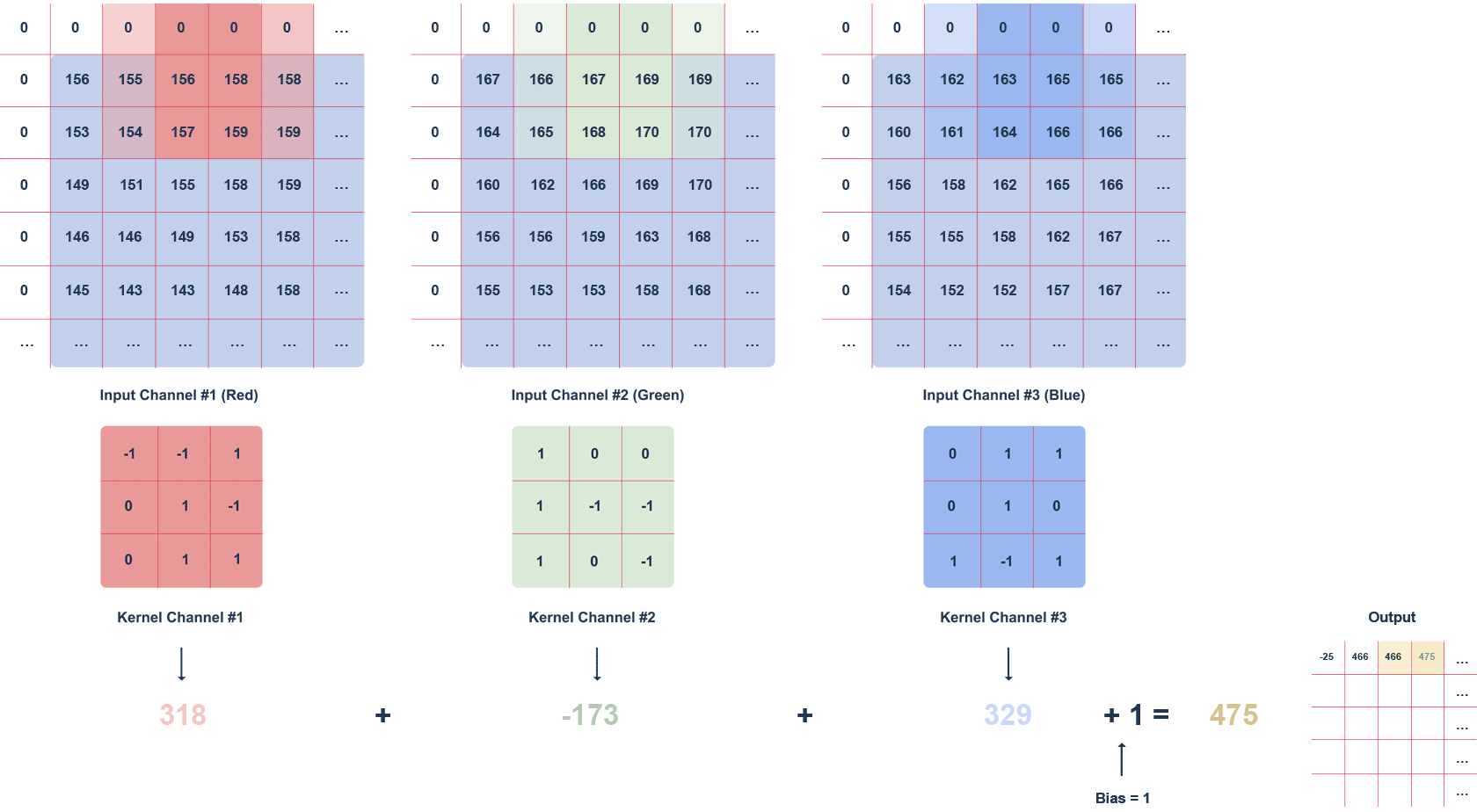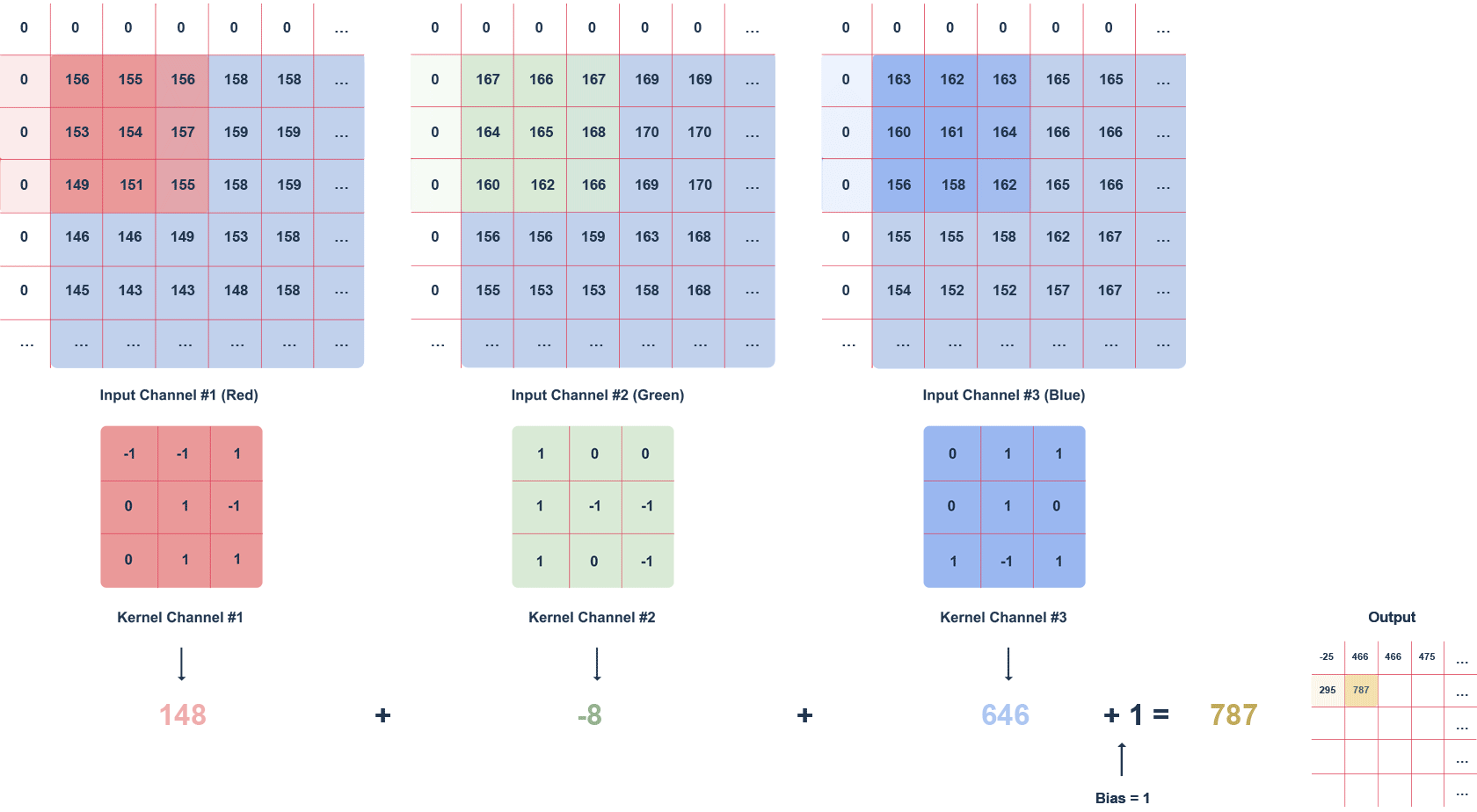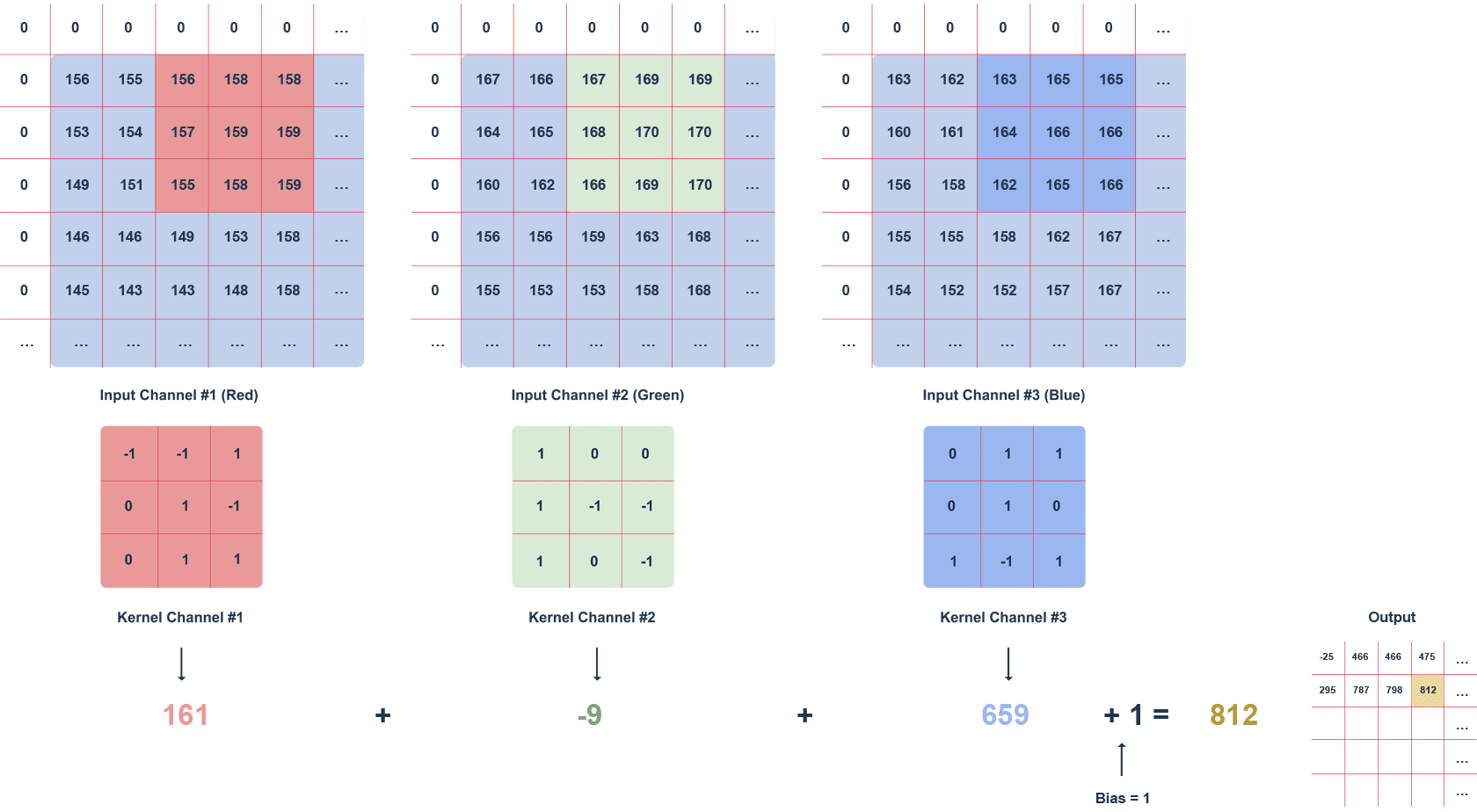
Powyższa animacja przedstawia obraz RGB oraz poruszający się po nim filtr o rozmiarze 3x3x3 i zdefiniowanym kroku. Krok to wartość w pikselach, o którą przesuwa się filtr. Może zostać zastosowany „zero padding”, czyli wypełnienie zerami (białe kwadraty). Taki zabieg pozwala na zachowanie większej ilości informacji, kosztem wydajności.
Kolejne wartości macierzy wyjściowej obliczane są w następujący sposób:
- mnożenie wartości w danym fragmencie obrazu przez filtr (po elementach),
- sumowanie obliczonych wartości dla danego kanału,
- sumowanie wartości dla każdego kanału z uwzględnieniem biasu (w tym przypadku równego 1).
Warto zwrócić uwagę, że wartości filtru dla danego kanału mogą się od siebie różnić. Zadaniem warstwy konwolucyjnej, w przypadku pierwszej warstwy, jest wyodrębnienie cech, takich jak krawędzie, kolory, gradienty. Kolejne warstwy sieci – korzystając z tego, co wyznaczyły poprzednie warstwy – mogą wykrywać coraz bardziej skomplikowane kształty. Analogicznie do warstw zwykłej sieci, po warstwie konwolucyjnej występuje warstwa aktywacyjna (najczęściej funkcja ReLU), wprowadzająca nieliniowość do sieci.
Wynik konwolucji z każdym z filtrów możemy interpretować jako obraz, a wiele takich obrazów powstałych poprzez konwolucję z wieloma filtrami to obraz o wielu kanałach. Obraz RGB to coś analogicznego – składa się z 3 kanałów, po jednym dla każdego z kolorów. Wyjście warstwy konwolucyjnej to nie są jednak kolory, lecz pewne „koloro-kształty”, które każdy z filtrów sobą reprezentuje. Odpowiada również za redukcję szumu. Najpopularniejszą metodą jest „max pooling”.
Zazwyczaj stosuje się wiele filtrów, przez co warstwa konwolucyjna, zwiększa głębokość, czyli liczbę kanałów obrazu.
Warstwa łącząca
Kolejna warstwa, nazywana łączącą ma za zadanie zmniejszenie pozostałych wymiarów obrazu (szerokości i wysokości), przy zachowaniu kluczowych informacji potrzebnych np. do klasyfikacji obrazu.

Operacja łączenia przebiega w sposób zbliżony do stosowanego w warstwie konwolucyjnej. Definiowany jest filtr oraz krok. Kolejne wartości macierzy wyjściowej są maksymalną wartością objętą filtrem.
Wymienione warstwy stanowią razem jedną warstwę sieci konwolucyjnej. Po zastosowaniu wybranej ilości warstw otrzymana macierz zostaje „spłaszczona” do jednego wymiaru – wymiary szerokość i wysokość są stopniowo zastępowane przez wymiar głębokości. Wynik warstw konwolucyjnych stanowi wejście do kolejnych warstw sieci, zazwyczaj takich standardowych, w pełni połączonych (ang. Dense Layers). Pozwala to na nauczenie algorytmu nieliniowych zależności pomiędzy cechami wyznaczonymi przez warstwy konwolucyjne.
Ostatnią warstwą sieci jest warstwa Soft-Max, pozwalająca na uzyskanie wartości prawdopodobieństw przynależności do poszczególnych klas (na przykład prawdopodobieństwo, że na obrazie znajduje się kot). W trakcie treningu są one porównywane z pożądanym wynikiem klasyfikacji w zastosowanej funkcji kosztu, a następnie poprzez algorytm wstecznej propagacji sieć dostosowuje swoje wagi w celu zminimalizowania błędu.
Konwolucyjne sieci neuronowe są ważnym elementem rozwoju uczenia maszynowego. Przyczyniają się do postępu automatyzacji i pozwalają rozszerzyć ludzkie zdolności percepcji. Ich możliwości będą stale rosnąć wraz z mocą obliczeniową komputerów i ilością dostępnych danych.
Bibliografia
[1] https://medium.com/@raycad.seedotech/convolutional-neural-network-cnn-8d1908c010ab