Mining has accompanied mankind since the dawn of time. The coming years are likely to bring yet another milestone in its development: space mining.
Visions vs reality
Space mining has long fuelled the imagination of writers and screenwriters. They paint a picture of a struggle for resources between states, corporations and cultures inhabiting various regions of the universe. Some also speak of the risks faced by humanity due to possible encounters with other life forms. There is also the topic of extremely valuable minerals and other substances that are unknown on Earth but may be obtained in space.
At the moment, however, these visions are far from becoming a reality. We are in the process of cataloguing space resources, e.g. by making geological maps of the Moon [1] and observing asteroids [2]. Interestingly, the Moon is known to contain deposits of helium-3, which could be used as fuel for nuclear fusion reactions in the future. We expect to find deposits of many valuable minerals on asteroids. For example, nickel, iron, cobalt, water, nitrogen, hydrogen and ammonia available on the asteroid Ryugu. Our knowledge of space mineral resources is based mainly on astronomical observations. Direct analysis of surface rock samples for this purpose is much rarer, and analysis of subsurface rocks takes place incidentally. We can only fully analyse objects that have fallen on the Earth’s surface. As such, we should expect many more surprises to come.
First steps in space mining
What will the beginnings look like? As an activity closely linked to the economy, mining will start to develop to meet the needs of the market. Contrary to what we are used to on Earth, access to even basic resources like water can prove problematic in space.
Water
Water can be used directly by humans, and after hydrolysis, it can also serve as fuel. Thus, the implementation of NASA’s plans for a manned expedition to Mars, which will be preceded by human presence on the Moon[3], will result in a demand for water on and near the Moon. Yet another significant market for space water could be satellites. All the more so since estimations indicate that it will be more profitable to bring water from the Moon than from the Earth even into Low Earth Orbit (LEO).
For these reasons, industrial water extraction on the Moon has the potential to be the first manifestation of space mining. What could this look like in practice? Due to the intense ultraviolet radiation, any ice on the lunar surface would have decomposed into oxygen and hydrogen long ago. However, since the Moon lacks an atmosphere, these elements would inevitably escape into space. Ice is thus expected in permanently shaded areas, such as the bottoms of impact craters at the poles. One method of mining ice could be to evaporate it in a sealed and transparent tent. The energy could be sourced from the sun: one would only need to reflect sunlight using mirrors placed at the craters’ edges. At the North Pole, you can find places where the sun shines virtually all the time.
Regolith
One of the first rocks to be harvested on the Moon is likely to be regolith. Regolith is the dust that covers the Moon’s surface) While regolith may contain trace amounts of water, it is mainly hoped that it could be used for 3D printing. This would make it possible to quickly and cheaply construct all the facilities of the planned lunar base[4]. The facilities of such a base will need to protect humans against harmful cosmic radiation. And although regolith, compared to other materials, is not terribly efficient when used as radiation shielding (you need a thick layer of it), its advantage is that you do not need to ferry it from Earth.
Generally speaking, the ability to use local raw materials to the highest extent possible is an important factor in the success of space projects to create sustainable extraterrestrial habitats. Thus, optimising these processes is a key issue (clickhere to learn more about industry optimisation opportunities).
Asteroids
Another direction for space mining could be asteroids[5]. Scientists are considering capturing smaller asteroids and bringing them back to Earth. It is also possible to bring both smaller and larger asteroids into orbit and mine them there. Yet another option is to mine asteroids without moving them. Then only deliver the excavated material, perhaps after initial processing, to Earth.
Legal barriers
One usually overlooked issue is that apart from the obvious technological and financial constraints, the legal issues surrounding the commercial exploitation of space can prove to be a major barrier[6]. As of today, the four most important international space regulations are as follows[7]:
1967 Outer Space Treaty,
1968 Astronaut Rescue Agreement,
1972 Convention on International Liability for Damage Caused by Space Objects, and
1975 Convention on the Registration of Objects Launched into Outer Space.
They formulate the principles of the freedom and non-exclusivity of space. Also, there is description about the treatment of astronauts as envoys of mankind and the attribution of nationality to every object sent into space. They also regulate the issue of liability for damage caused by objects sent into space. However, they do not regulate the economic matters related to space exploitation. This gap is partly filled by the 1979 Moon Agreement. Although few states have ratified it (18), it aspires to create important customary norms for the coverage of space by legal provisions.
Among other things, it stipulates that the Moon’s natural resources are the common heritage of mankind and that neither the surface nor the resources of the Moon may become anyone’s property[8]. The world’s most affluent countries are reluctant to address its provisions. In particular, the US has officially announced that it does not intend to comply with the Agreement. Could it be that asteroid mining is set to become part of some kind of space colonialism?
A data warehouse is one of the more common topics in the IT industry. The collected data is an important source of valuable information for many companies, thus increasing their competitive advantage. More and more companies use Business Intelligence (BI) systems in their work, which quickly and easily support the analytical process. BI systems are based on data warehouses and we will talk about them in today’s article.
What is a data warehouse?
A data warehouse is one of the more common topics in the IT industry. The collected data is an important source of valuable information for many companies, thus increasing their competitive advantage. More and more companies use Business Intelligence (BI) systems in their work, which quickly and easily support the analytical process. BI systems are based on data warehouses and we will talk about them in today’s article.
Characteristics
There are four main features that characterize a data warehouse. These are:
Subject orientation – the collected data is organized around main topics such as sales, product, or customer;
Integrity – the stored data is uniform, e.g. in terms of format, nomenclature, and coding structures. They are standardized before they reach the warehouse;
Timeliness – the data comes from different time frames, it contains both historical and current data;
Non-volatile – the data in the warehouse remains unchanged. The user cannot modify it, so we can be sure that we will get the same results every time.
Architecture and operation
In the architecture of a data warehouse, four basic components can be distinguished. Data sources, ETL software, the appropriate data warehouse, and analytical applications. The following graphic shows a simplified diagram of that structure.
Img 1 Diagram of data warehouse operation
As can be seen from the graphic above, the basis for building each data warehousing system is data. The sources of this data are dispersed – they include ERP, CRM, SCM, or Internet sources (e.g. statistical data).
The downloaded data is processed and integrated and then loaded into a proper data warehouse. This stage is called the ETL process, from the words: extract, transform and load. According to the individual stages of the process, data is first taken from available sources (extract). In the next step, the data is transformed, i.e. processed in an appropriate way (cleaning, filtering, validation, or deleting duplicate data). The last step is to load the data to the target database, i.e. the data warehouse.
As we mentioned earlier, the data collected is read-only. Users call data from the data warehouse using appropriate queries. On this account, obtaining data is presented in a more friendly form, i.e. reports, diagrams, or visualizations.
Main tasks
As the main task of a data warehouse, analytical data processing (OLAP, On-Line Analytical Processing) should be distinguished. It allows for making various types of summaries, reports, or charts presenting significant amounts of data. For example, a sales chart in the first quarter of the year, a report of products generating the highest revenue, etc.
The next task of that tool is decision support in enterprises (DSS, Decision Support System). Taking into account the huge amount of information that is in the data warehouses, they are a part of the decision support system for companies. Thanks to advanced analyses conducted with the use of these databases, it is much easier to search for dominant trends, models, or relations between various factors, which may facilitate managerial decision-making.
Another of the tasks of these specific databases is to centralize data in the company. Data from different departments/levels of the company are collected in one place. Thanks to that, everyone interested has access to them whenever he or she needs them.
Centralization is connected with another role of a data warehouse, which is archiving. Because the data collected in the warehouse comes from different periods and the warehouse is supplied with new, current data on an ongoing basis, it also becomes an archive of data and information about the company.
Summary
Data warehousing is undoubtedly a useful and functional tool that brings many benefits to companies. Implementation of this database in your company may facilitate and speed up some of the processes taking place in companies. An enormous amount of data and information is generated every day. Therefore, data warehouses are a perfect answer to store this information in one, safe place, accessible to every employee. If you want to introduce a data warehousing system to your company, check our product Data Engineering.
During their education, musicians need to acquire the ability to play a vista, that is, to play an unfamiliar piece of music without having a chance to get familiar with it beforehand. Thanks to this, virtuosos can not only play most pieces without preparation but also need much less time to learn the more demanding ones. However, it takes many a musical piece for one to learn how to play a vista. The pieces used for such practice should be little-known and matched to the skill level of the musician concerned. Therefore, future virtuosos must devote a lot of their time (and that of their teachers) to preparing such a playlist, which further discourages learning. Worse still, once used, a playlist is no longer useful for anything.
The transistor composer
But what if we had something that could prepare such musical pieces on its own, in a fully automated way? Something that could not only create the playlist but also match the difficulty of the musical pieces to the musician’s skill level. This idea paved the way for the creation of an automatic composer — a computer programme that composes musical pieces using artificial intelligence, which has been gaining popularity in recent times.
Admittedly, the word “composing” is perhaps somewhat of an exaggeration and the term “generating” would be more appropriate. Though, after all, composers create musical pieces based on their own algorithms. Semantics aside, what matters here is that such a (simple, for the time being) programme has been successfully created and budding musicians could benefit from it.
However, before we discuss how to generate musical pieces, let us first learn the basics of how musical pieces are structured and what determines their difficulty.
Fundamentals of music
The basic concepts in music include the interval, semitone, chord, bar, metre, musical scale and key of a musical piece. An interval is a quantity that describes the distance between two consecutive notes of a melody. Although its unit is the semitone, it is common practice to use the names of specific intervals. In contrast, a semitone is the smallest accepted difference between pitches (approximately 5%). While these differences can be infinitely small, it is simply that this division of intervals has become accepted as standard. A chord is three or more notes played simultaneously. The next concept is the bar, which is what lies between the vertical dashes on the stave. Sometimes a musical piece may begin with an incomplete bar (anacrusis).
Figure 1 Visualisation of an anacrusis
Metre — this term refers to how many rhythmic values are in one bar. In 4/4 metre, there should be four quarter notes to each bar. In 3/4 metre, there should be three quarter notes to each bar while 6/8 metre should have six eighth notes to each bar. Although 3/4 and 6/8 denote the same number of rhythmic values, these metres are different, the accents in them falling on different places in the bar. In 3/4 metre, the accent falls on the first quarter note (to put it correctly, “on the downbeat”). By comparison, in 6/8 metre, the accent falls on the first and fourth measures of the bar.
A musical scale is a set of sounds that define the sound material that musical works use. The scales are ordered appropriately — usually by increasing pitch. The most popular scales are major and minor. While many more scales exist, these two predominate in the Western cultural circle. They were used in most of the older and currently popular pieces. Another concept is key, which identifies the tones that musical pieces use. In terms of scale vs. key, scale is a broader term; there are many keys of a given scale, but each key has its own scale. The key determines the sound that the scale starts with.
Structure of a musical piece
In classical music, the most popular principle for shaping a piece of music is periodic structure. The compositions are built using certain elements, i.e. periods, which form a separate whole. However, several other concepts must be introduced to explain them.
A motif is a sequence of several notes, repeated in the same or slightly altered form (variation) elsewhere in the work. Typically, the duration of a motif is equal to the length of one bar.
A variation of a motif is a form of the motif that has been altered in some way but retains most of its characteristics, such as rhythm or a characteristic interval. musical pieces do not contain numerous motifs at once. A single piece is mostly composed of variations of a single motif. Thanks to this, each musical piece has a character of its own and does not surprise the listener with new musical material every now and then.
A musical theme is usually a sequence of 2-3 motifs that are repeated (possibly in slightly altered versions) throughout the piece. Not every piece of music needs to have a theme.
A sentence is two or more phrases.
A period is defined by the combination of two musical sentences. Below is a simple small period with its basic elements highlighted.
Figure 2 Periodic structure diagram of a musical piece
This is roughly what the periodic structure looks like. Several notes form a motif, a few motifs create a phrase, a few phrases comprise a sentence, a few sentences make up a period, and finally, one or more periods form a whole musical piece. There are also alternative methods of creating musical pieces. However, the periodic structure is the most common, and importantly in this case, easier to program.
Composing in harmony
Compositions are typically based on harmonic flows — chords that have their own “melody” and rhythm. The successive chords in the harmonic flows are not completely random. For example, the F major and G major chords are very likely to be followed by C major. By contrast, it is less likely to be followed by E minor and completely unlikely to be followed by Dis major. There are certain rules governing these chord relationships. However, we do not need to delve into them further since we will be using statistical models to generate song harmonies.
Instead, we need to understand what harmonic degrees are. Keys have several important chords called triads. Their basic sound, the root notes, are the subsequent notes of a given key. The other notes belong to this key, e.g. the first degree of the C major key is the C major chord, the second degree the D minor chord, the third degree the E minor chord, and so on. Harmonic degrees are denoted by Roman letters; major chords are usually denoted by capital letters and minor chords by small letters (basic degrees of the major scale: I, II, III, IV, V, VI, VII).
Harmonic degrees are such “universal” chords; no matter what tone the key starts with, the probabilities of successive harmonic degrees are the same. In the key of C major, the C – F – G – C chord sequence is just as likely as the sequence G – C – D – G in the key of G major. This example shows one of the most common harmonic flows used in music, expressed in degrees: I – IV – V – I
Melody sounds are not completely arbitrary; they are governed by many rules and exceptions. Below is an example of a rule and an exception in creating harmony:
Rule: for every measure of a bar, there should be a sound belonging to the given chord,
Exception: sometimes other notes that do not belong to the chord are used for a given measure of the bar; however, they are then followed relatively quickly by a note of this chord.
These rules and exceptions in harmony do not have to be strictly adhered to. However, if one does comply with them, there is a much better chance that one’s music will sound good and natural.
Factors determining the difficulty of a musical piece
Several factors influence the difficulty of a piece of music:
tempo — in general, the faster a musical piece is, the more difficult it gets, irrespective of the instrument, (especially when playing a vista)
melody dynamics — a melody consisting of two sounds will be easier to play than one that uses many different sounds
rhythmic difficulty — the more complex the rhythm, the more difficult the musical piece. The difficulty of a musical piece increases as the number of syncopations, triplets, pedal notes and similar rhythmic “variety” grows higher.
repetition — no matter how difficult a melody is, it is much easier to play if parts of it are repeated, as opposed to one that changes all the time. It is even worse in cases where the melody is repeated but in a slightly altered, “tricky” way (when the change of melody is easy to overlook).
difficulties related to musical notation — the more extra accidentals (flats, sharps, naturals), the more difficult a musical piece is
instrument-specific difficulties – some melodic flows can have radically different levels of difficulty on different instruments, e.g. two-note tunes on the piano or guitar are much easier to play than two-note tunes on the violin
Some tones are more difficult than others because they have more key marks to remember.
Technical aspects of the issue
Since we have outlined the musical side in the previous paragraphs, we will now focus on the technical side. To get into it properly, it is necessary to delve into the issue of “conditional probability”. Let us start with an example.
Suppose we do not know where we are, nor do we know today’s date. What is the likelihood of it snowing tomorrow? Probably quite small (in most places on Earth, it never or hardly ever snows) so we will estimate this likelihood at about 2%. However, we have just found out that we are in Lapland. This land is located just beyond the northern Arctic Circle. Bearing this in mind, what would the likelihood of it snowing tomorrow be now? Well, it would be much higher than it had been just now. Unfortunately, this information does not solve our conundrum since we do not know the current season. We will therefore set our probability at 10%. Another piece of information that we have received is that it is the middle of July — summer is in full swing. As such, we can put the probability of it snowing tomorrow at 0.1%.
Conditional probability
The above story allows us to easily draw a conclusion. Probability depended on the state of our knowledge and could vary in both ways based on it. This is how conditional probabilities, which are denoted as follows, work in practice:
P(A|B)
They inform us of how probable it is for an event to occur (in this case, A) if some other events have occurred (in this case, B). An “event” does not necessarily mean an occurrence or incident — it can be, as in our example, any condition or information.
To calculate conditional probabilities we must know how often event B occurs and how often events A and B occur at the same time. It will be easier to explain it by returning to our example. Assuming that A is snow falling and B is being in Lapland, the probability of snow falling in Lapland is equal to:
The same equation, expressed more formally and using the accepted symbols A and B, would be as follows:
Note that this is not the same as the likelihood of it snowing in Lapland. Perhaps we visit Lapland more often in winter and it is very likely to snow when we are there?
Now, to calculate this probability exactly, we need two statistics:
NA∩B — how many times it snowed when we were in Lapland,
NB — how many times have we been to Lapland,
and how many days we have lived so far (or how many days have passed since we started keeping the above statistics):
NTOTAL.
We will use this data to calculate P(A∩B) and P(B) respectively:
At last, we have what we expected:
The probability of it snowing if we are in Lapland is equal to the ratio of how many times it snowed when we were in Lapland to how many times we were in Lapland. It is also worth adding that the more often we have been to Lapland, the more accurate this probability will be (if we have spent 1,000 days in Lapland, we will have a much better idea about it than if we have been there 3 times).
N-grams
The next thing we need to know before taking up algorithmic music composition is N-grams, that is, how to create them and how to use them to generate probable data sequences. N-grams are statistical models. One N-gram is a sequence of elements of length equal to N. There are 1-grams, 2-grams, 3-grams, etc. Such models are often used in language modelling. They make it possible to determine how probable it is for a sequence of words to occur.
To do that, you take a language corpus (lots of books, newspapers, websites, forum posts, etc.) and count how many times a particular sequence of words occurs in it. For example, if the sequence “zamek królewski” [English: king’s castle] occurs 1,000 times in the corpus and the sequence “zamek błyskawiczny” [English: zip fastener] occurs 10 times, this means that the first sequence is 100 times more likely than the second. Such information can prove useful to us. They allow us to determine how probable every sentence is.
The Internet of Things (IoT) is entering our lives at an increasingly rapid pace. Control of lighting or air conditioning commanded by smartphones is slowly becoming an everyday reality. Additionally, many companies more and more willingly introduce to their processes the solutions provided by IoT. According to the latest forecasts, by 2027 41 billion IoT devices will be connected to the internet. There is no doubt that IoT offers great opportunities. However, at the same time, there is no denying that it can also bring whole new threats. It is therefore worthwhile to be aware of the dangers that may be associated with the use of IoT.
Img 1 The total number of device installations for IoT
Threats
Hacking attacts
An extensive network of IoT devices creates many opportunities for hacking attacks. Whereby the space that could potentially be attacked increases with the amount of IoT devices in operation. It is enough that the attacker will hack into one of these devices and gain access to the entire network and to the data that flows through. This poses a real threat to both individuals and companies.
The loss of data
The loss of data is one of the most frequently mentioned threats posed by IoT. Improper storage of sensitive data such as names, addresses, PESEL (personal identity number), or payment card numbers can expose us to the danger of being used in an undesirable way for us (e.g. taking credit, stealing money). Moreover, based on data collected by home IoT devices, the attacker can easily learn about the habits of the household, which can facilitate sophisticated scams.
Botnet attact
Another threat is the risk of the IoT device being included in the so-called botnet. The botnet is a network of infected devices that hackers can use to carry out various types of attacks. Most often a common botnet attack is a DDoS attack (Distributed Denial of Service). It consists of combining the website with multiple devices at the same time, which can lead to its temporary unavailability. Another example of how a botnet works is the use of infected devices to send spam or produce a crypto valent. All these attacks are carried out in a manner unnoticeable to the owner of the device. It is enough that we click on a link from an unknown source that may contain malware. Then we unconsciously become part of a botnet attack.
Attacts on machines
From a company’s point of view, attacks on industrial robots and machines, which are connected to the network, can be a significant threat. Taking over control of such devices can cause serious damage to companies. For example, hackers can change the production parameters of a component in such a way that they will not be caught right away, but it will make this component useless. Attackers can also cause disturbances in the operation of machines or interruptions in energy supply. These activities are a serious threat to companies, that could suffer huge financial losses as a result.
How can we protect ourselves?
It may seem that it is impossible to eliminate the dangers of using IoT technology. However, there are solutions that we can implement to increase the safety of our devices. Here are some of them:
Strong password
An important aspect in the security of IoT devices is password strength. Very often users have simple passwords, containing data that is easy to identify (e.g. names or date of birth). It often happens that the password is the same for several devices, making it easier to access them. Also, sometimes users do not change the standard password that is set by the manufacturer of the device. It is therefore important that the password is not obvious. Increasingly often, manufacturers force users to have strong passwords by setting the conditions they must meet. It is demanded to use upper and lower-case letters, numbers, and special characters. This is a very good practice that can increase security on the network.
Software update
Another way is to regularly update the software used by IoT devices. If manufacturers will detect a vulnerability in their security, they can protect users from a potential attack. They can provide them with a new version of the software that eliminates the deficiencies detected. Ideally, the device should be set for automatic system updates. Then we can be sure that the device always works on the latest software version.
Secure home network
Securing your home network is as important as setting a strong access password. In this case, it is also recommended to change the original password set by the router provider. Additionally, the home Wi-Fi network should use an encrypted connection such as WPA2-PSK.
Consumptionary restraint
Before buying a given device, it is good to consider whether we need it. There is no point in treating it more just like a cool gadget. Let’s remember that every subsequent IoT device in our environment increases the risk of a potential attack.
All the above-mentioned actions are the ones, which should be taken by users of IoT devices. However, the manufacturer of the device also takes care of its protection, such as via the encryption of network messages, which secures the interception of data during transport is on its side. The most commonly used protection is the TLS protocol (Transport Layer Security). TLS protocol helps secure the data that is transmitted over the network. In addition, the manufacturer of the device should regularly check its security features, so that it will be able to catch any gaps and eliminate them. It is also good to keep the devices secure from the beginning before automatic connection to open public networks.
In June 2019 the Cybersecurity Act was established, which aims at strengthening the cyber security of EU Member States. It regulates the basic requirements to be met by products connecting to the network, which contributes to the safety of these devices. Rapid IoT development makes more similar regulations, which will significantly contribute to maintaining global cyber security.
Summary
The advent of IoT technology has brought a huge revolution, both for individuals and for the whole of companies. Although IoT brings many benefits and facilitations, you must also be aware that it may pose a threat to the security of our data or ourselves. However, it is worth remembering that compliance with a few of our principles can make a significant contribution to the safety of your IoT equipment.
Industrial noise is nowadays just as important a problem like air pollution or waste management. However, it seems to be less popular in the media. Meanwhile, it can equally affect our well-being or health. The Act of 27 April 2001 Environmental Protection Law treats noise as pollution. Therefore, the same general principles of conduct should be adopted for other environmental pollution, e.g. air or soil pollution.
Industrial noise is nowadays just as important a problem like air pollution or waste management. However, it seems to be less popular in the media. Meanwhile, it can equally affect our well-being or health. The Act of 27 April 2001 Environmental Protection Law treats noise as pollution. Therefore, the same general principles of conduct should be adopted for other environmental pollution, e.g. air or soil pollution.
The noise generated in industrial halls concerns the issue of noise in the workplace. Industrial halls are in the vast majority huge, often high spaces, through which noise generated by machines and people spreads. Depending on the size of the surface of such a hall, and the number of machines working on it, the noise problem can be large, but within certain standards. Unfortunately, in many cases, it exceeds acceptable norms, which has negative consequences.
Employee working conditions
The conditions in the workplace are precisely described in the act by which noise standards are defined. The Act sets the Maximum Permissible Intensity (pol. Najwyższe Dopuszczalne Natężenie). Maximum Permissible Intensity means the intensity of a physical factor harmful to health, whose impact during work should not cause negative changes in the employee’s state of health. For 8-hour or weekly operation it is 85 dB. If the noise exceeds this standard continuously, it may cause problems for employee health. Moreover, a company can be exposed to penalties due to the lack of proper working conditions.
What if the noise is more than the allowable 85 dB, but through the day’s work? In this case, appropriate recommendations are also adopted. Work in constant noise within 95-100 dB may not last more than 40-100 minutes a day. Working in noise up to 110 dB can’t exceed more than 10 minutes a day.
How can we handle industrial noise?
One of the most common ways to protect employees’ health against noise is to equip them with noise-absorbing earmuffs. There are many types of such devices on the market that are equipped e.g. with a noise reduction system. Often they even enable communication between employees without removing the device. However, this is not a specific solution that prevents the occurrence of noise or vibration of working machines. It just limits the effects of their impact on employees working in this place.
The appearance of the production halls is also an important issue. For new halls, at the design stage solutions that effectively reduce the spread of noise are taken into account. It is difficult to apply such solutions in halls that are outdated or have limited reconstruction possibilities. The costs of such modernizations are usually too high above the effects. Considering these issues, other noise reduction methods must be used including active and passive methods.
Active Noise Control
Active Noise Control (ANC) is a method of reducing unwanted sound by adding another sound source specially designed to cancel the original noise. Adding noise and anti-noise together allows you to achieve a more satisfactory result. BFirst.tech has its own ANC solution, which is equipped with an artificial intelligence algorithm that allows reduction of industrial noise to an acoustic background level in the range of 50-500 Hz.
Img 1 Active Noise Control device enclosure
The system includes an algorithm of real-time adaptation to industrial noise changes. For example, the advantage of such a solution is that it does not work rigidly after programming, but can react to changes in machine operation, e.g. a change in the rotational speed of the mechanical system. The system is designed for both open and closed rooms, which means that it is ideal for industrial halls.
Passive Noise Control
Noise problems can be solved in many ways. Another option is to use passive methods. Passive methods are e.g. systems of acoustic systems in the case of noise (absorbers, mats, acoustic panels) or Vibro-isolating systems. The key to properly designing passive solutions is to study the work environment, locate sources of noise and how it propagates, and tailor efficient solutions to it. These solutions are primarily the arrangement of individual elements in the work environment and the selection of materials with parameters that will effectively absorb the resulting noise.
What path to choose?
To effectively fight noise and vibrations in industry and the environment we offer our innovative solution Intelligent Acoustics. If you want to read more about the functionalities of Intelligent Acoustics, click here.
GANs, i.e. Generative Adversarial Networks, were first proposed by University of Montreal students Ian Goodfellow and others (including Yoshua Bengio) in 2014. In 2016, Facebook’s AI research director and New York University professor Yann LeCun called them “the most interesting idea in the last 10 years in machine learning”.
In order to understand what GANs are, it is necessary to compare them with discriminative algorithms like the simple Deep Neural Networks (DNNs). For an introduction to neural networks, please see this article. For more information on Convolutional Neural Networks, click here.
Let us use the issue of predicting whether a given email is spam or not as an example. The words that make up the body of the email are variables that determine one of two labels: “spam” and “non-spam”. The discriminator algorithm learns from the input vector (the words occurring in a given message are converted into a mathematical representation) to predict how much of a spam message the given email is, i.e. the output of the discriminator is the probability of the input data being spam, so it learns the relationship between the input and the output.
GANs do the exact opposite. Instead of predicting what the input data represents, they try to predict the data while having a label. More specifically, they are trying to answer the following question: assuming this email is spam, how likely is this data?
Even more precisely, the task of Generative Adversarial Networks is to solve the issue of generative modelling, which can be done in 2 ways (you always need high-resolution data, e.g. images or sound). The first possibility is density estimation — with access to numerous examples, you want to find the density probability function that describes them. The second approach is to create an algorithm that learns to generate data from the same training dataset (this is not about re-creating the same information but rather creating new information that could be such data).
What generative modelling approach do GANs use?
This approach can be likened to a game played by two agents. One is a generator that attempts to create data. The other is a discriminator that predicts whether this data is true or not. The generator’s goal is to cheat the other player. So, over time, as both get better at their task, it is forced to generate data that is as similar as possible to the training data.
What does the learning process look like?
The first agent, i.e. the discriminator (it is some differentiable function D, usually a neural network), gets a piece of the training data as input (e.g. a photo of a face). This picture is then called x (it is simply the name of the model input) and the goal is for D(x) to be as close to 1 as possible — meaning that x is a true example.
The second agent, i.e. the generator (differentiable function G; it is usually a neural network as well), receives white noise z (random values that allow it to generate a variety of plausible images) as input. Then, applying the function G to the noise z, one obtains x (in other words, G(z) = x). We hope that sample x will be quite similar to the original training data but will have some problems — such as noticeable noise — that may allow the discriminator to recognise it as a fake example. The next step is to apply the discriminant function D to the fake sample x from the generator. At this point, the goal of D is to make D(G(z)) as close to zero as possible, whereas the goal of G is for D(G(z)) to be close to one.
This is akin to the struggle between money counterfeiters and the police. The police want the public to be able to use real banknotes without the possibility of being cheated, as well as to detect counterfeit ones and remove them from circulation, and punish the criminals. At the same time, counterfeiters want to fool the police and use the money they have created. Consequently, both the police and the criminals are learning to do their jobs better and better.
Assuming that the hypothetical capabilities of the police and the counterfeiters — the discriminator and the generator — are unlimited, then the equilibrium point of this game is as follows: the generator has learned to produce perfect fake data that is indistinguishable from real data, and as such, the discriminator’s score is always 0.5 — it cannot tell if a sample is true or not.
What are the uses of GANs?
GANs are used extensively in image-related operations. This is not their only application, however, as they can be used for any type of data.
Figure 1 Style Transfer carried out by CycleGAN
For example, the DiscoGAN network can transfer a style or design from one domain to another (e.g. transform a handbag design into a shoe design). It can also generate a plausible image from an item’s sketch (many other networks can do this, too, e.g. Pix2Pix). Known as Style Transfer, this is one of the more common uses of GANs. Other examples of this application include the CycleGAN network, which can transform an ordinary photograph into a painting reminiscent of artworks by Van Gogh, Monet, etc. GANs also enable the generation of images based on a description (StackGAN network) and can even be used to enhance image resolution (SRGAN network).
[3] White T., Sampling Generative Networks, School of Design, Victoria University of Wellington, Wellington
[4] LeCun Y., Mathieu M., Zhao J., Energy-based Generative Adversarial Networks, Department of Computer Science, New York University, Facebook Artificial Intelligence Research, 2016, https://arxiv.org/pdf/1609.03126v2.pdf
References
[1] Goodfellow I., Tutorial: Generative Adversarial Networks [online], “NIPS”, 2016, https://arxiv.org/pdf/1701.00160.pdf [2] Skymind, A Beginner’s Guide to Generative Adversarial Networks (GANs) [online], San Francisco, Skymind, accessed on: 31 May 2019 [3] Goodfellow, Ian, Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, and Bengio, Yoshua. Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680, 2014 [4] LeCun, Y., What are some recent and potentially upcoming breakthroughs in deep learning?, “Quora”, 2016, accessed on: 31 May 2019, https://www.quora.com/What-are-some-recent-and-potentially-upcoming-breakthroughs-in-deep-learning [5] Kim T., DiscoGAN in PyTorch, accessed on: 31 May 2019, https://github.com/carpedm20/DiscoGAN-pytorch
Artificial intelligence elevates the capabilities of the machines closer to human-like level at an increasing rate. Since it is an issue of great interest, many fields of science have taken a big leap forward in recent years.
One of the goals of artificial intelligence is to enable machines to observe the world around them in a human-like way. This is possible through the application ofneural networks. Neural networks are mathematical structures that, at their base, are inspired by the natural neurons found in the human nerves and brain.
Surely you have felt the presence of neural networks in everyday life many times, for example in:
face detection and recognition in smartphone photos,
recognition of voice commands by the virtual assistant,
autonomous cars.
The potential of neural networks is enormous. The examples listed above represent merely a fraction of current applications. They are, however, related to a special class of neural networks, called convolutional neural networks, CNNs, or ConvNet (Convolutional Neural Networks).
Image processing and neural networks
To explain the idea of convolutional neural networks, we will focus on their most common application –image processing. A CNN is an algorithm that can take an input image and classify it according to predefined categories (e.g. the breed of dog). This is be achieved by assigning weights to different shapes, structures, objects.
Convolutional networks, through training, are able to learn which specific features of an image help to classify it. Their advantage over standard deep networks is that they are more proficient at detecting intricate relationships between images. This is possible thanks to the use of filters that examine the relationship between adjacent pixels.
Figure 1 General RGB image sizing scheme
Each image is a matrix of values, the number of which is proportionate to its width and height in pixels. For RGB images, the image is characterised by three primary colours, so each pixel is represented by three values. ConvNet’s task is to reduce the size of the image to a lighter form. However, it happens without losing valuable features, i.e. those that carry information crucial for classification.
CNN has two key layers. The first one is convolutional layer.
Convulational layer
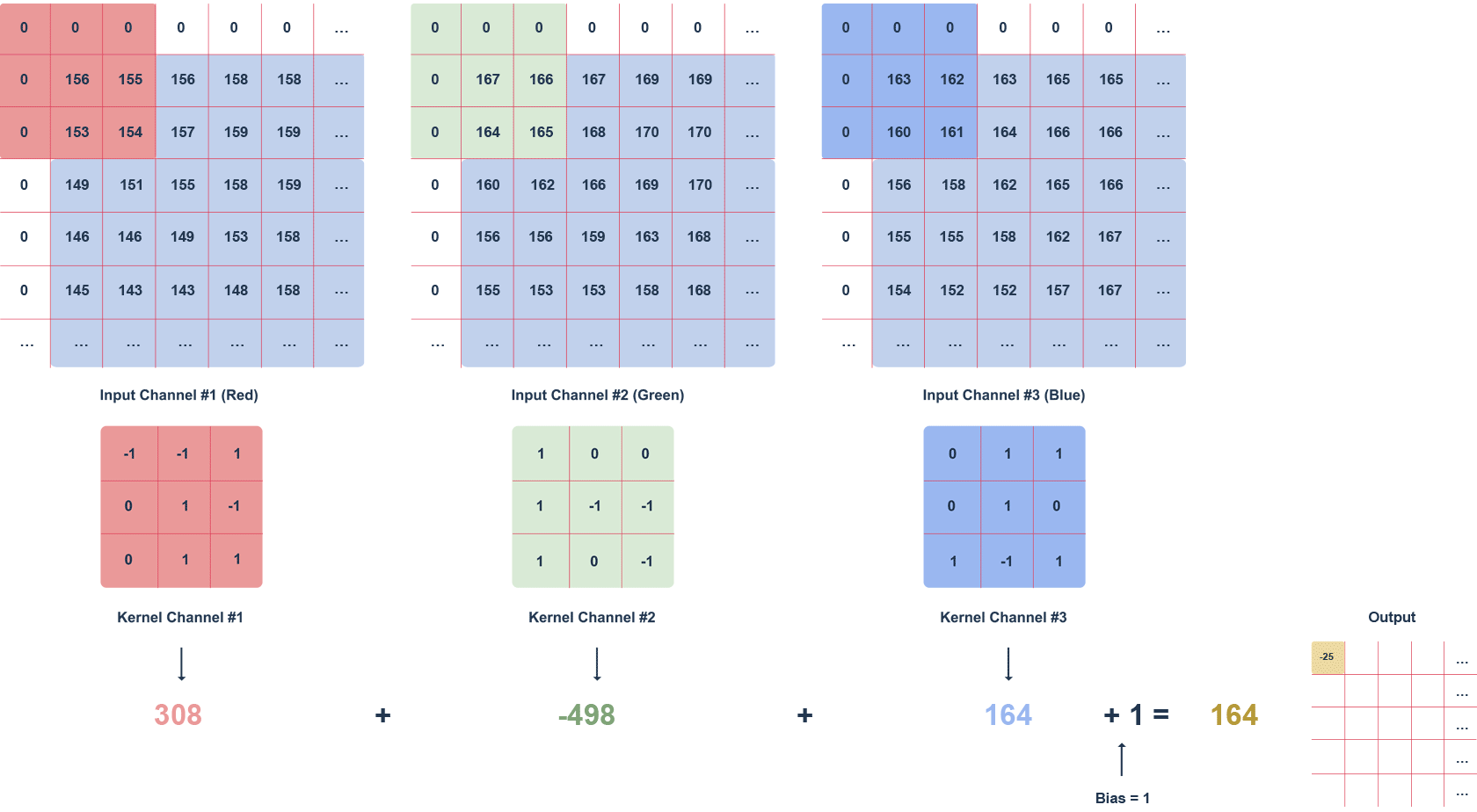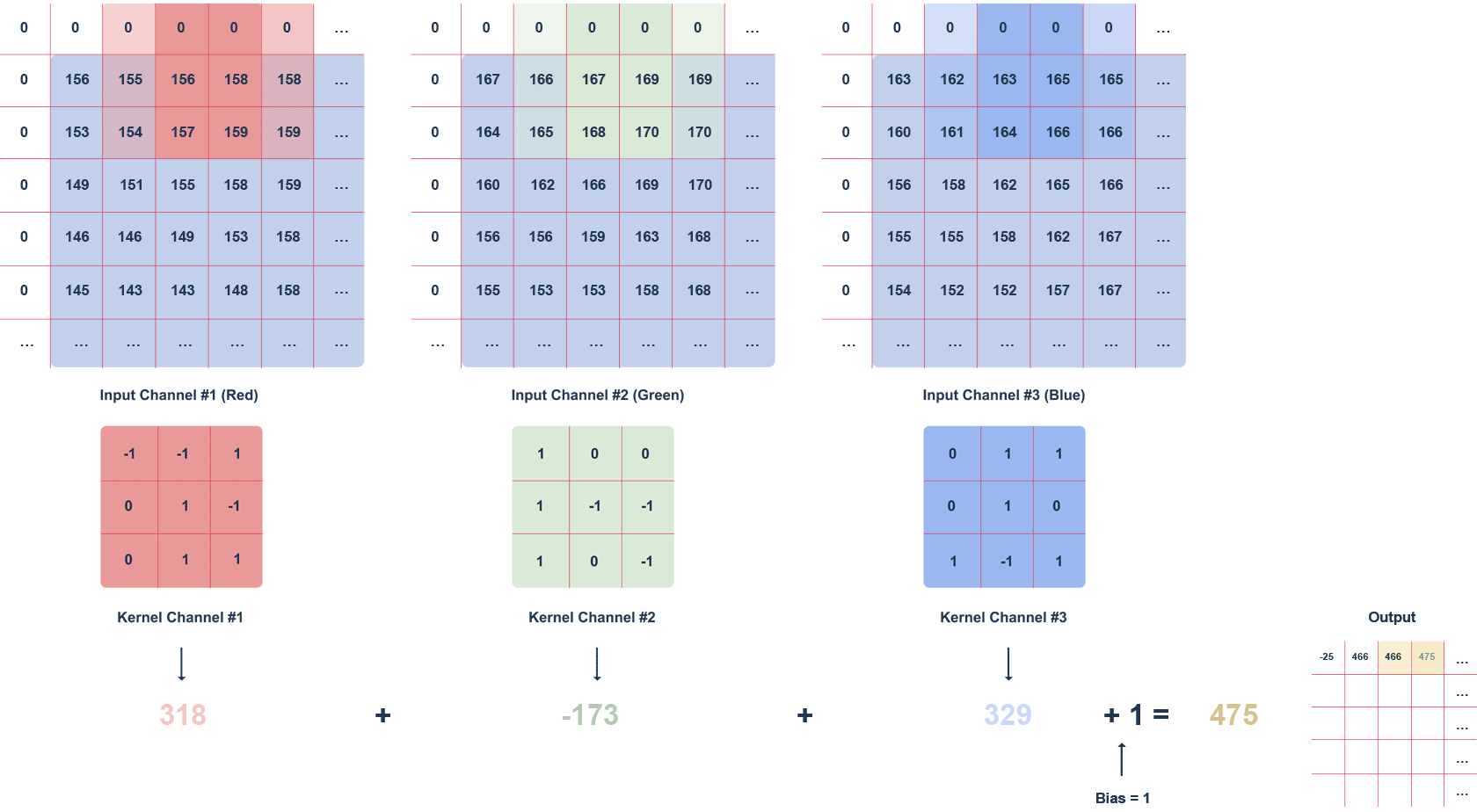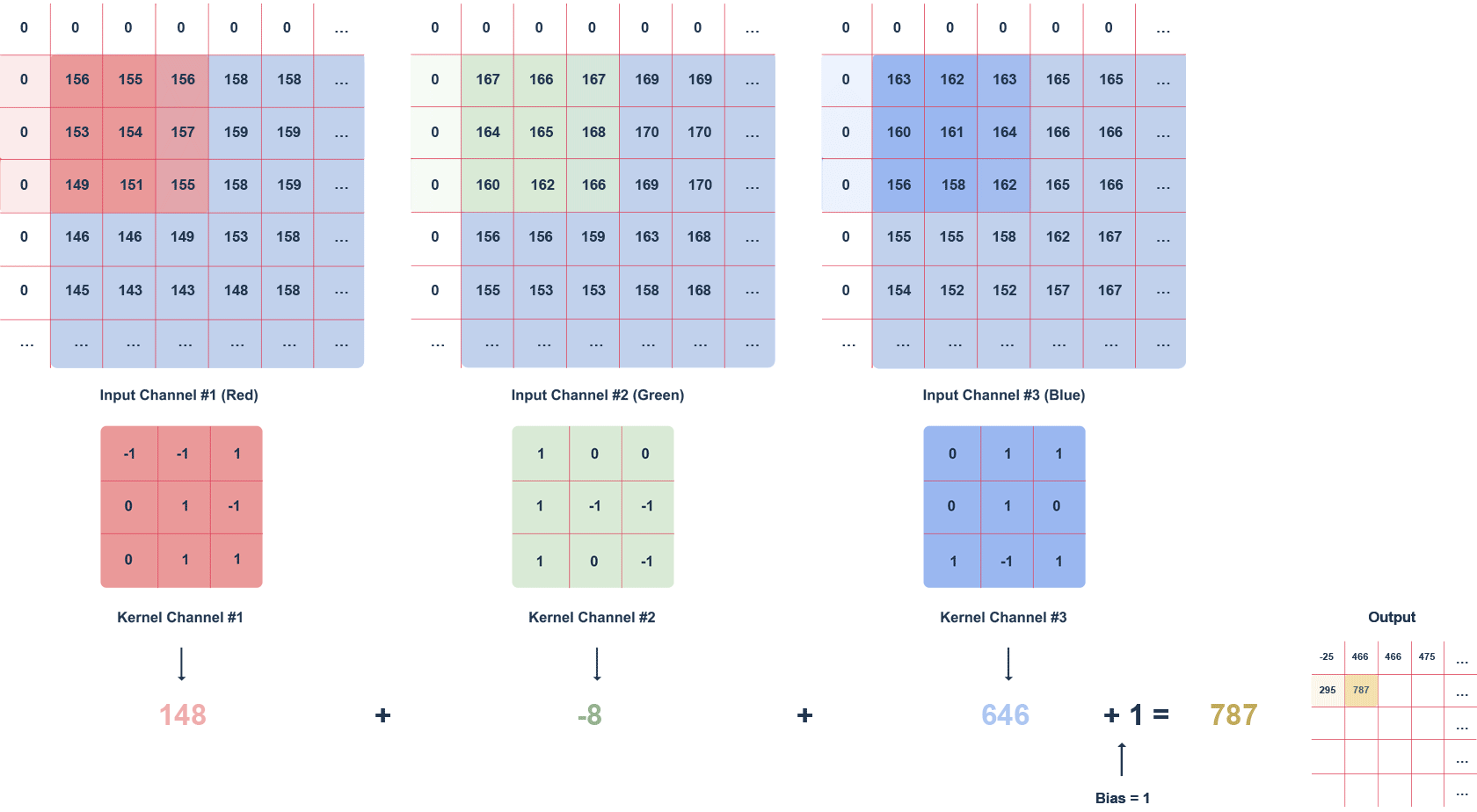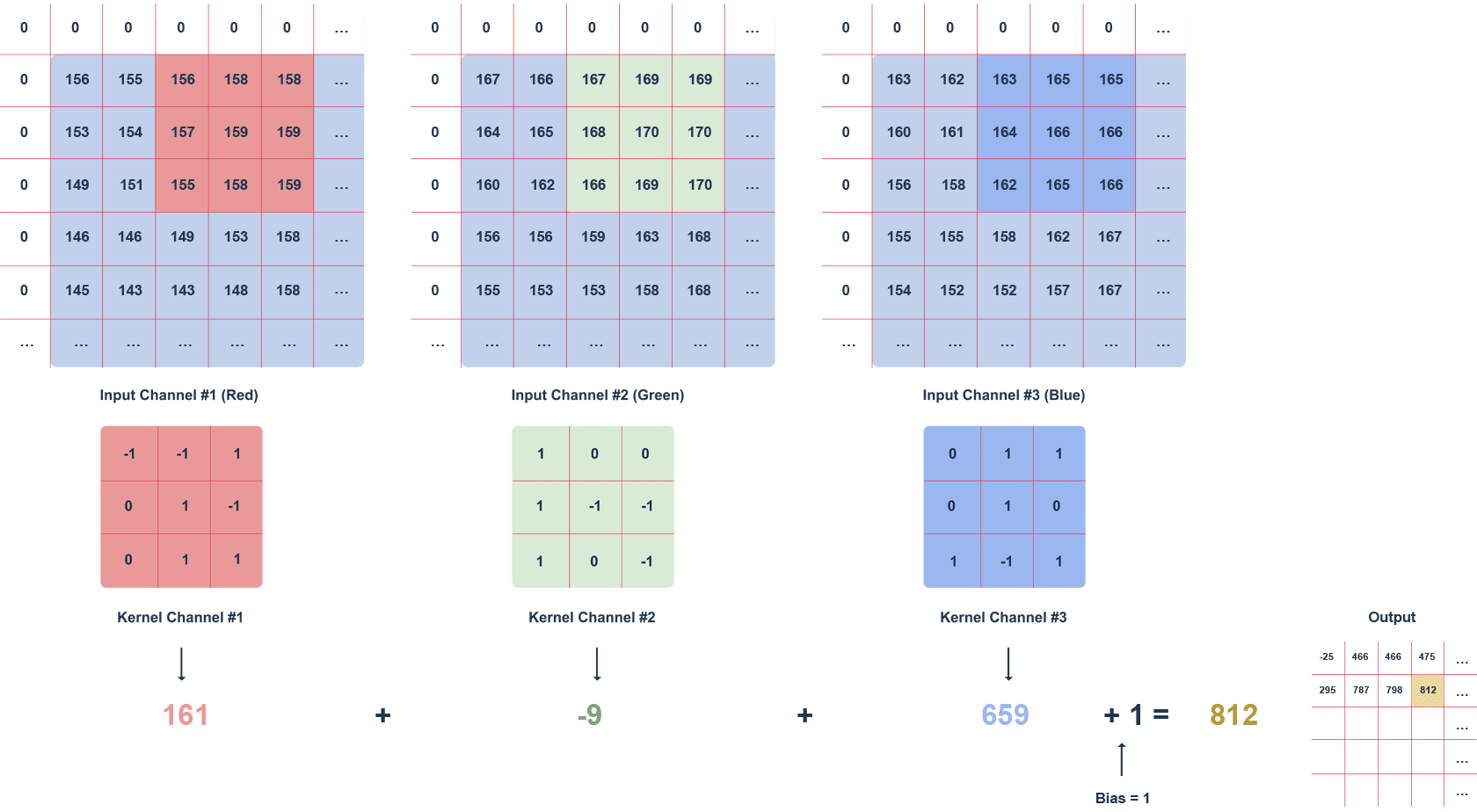
Figure 2 Animation of RGB image filtering with a 3x3x3 filte
The animation above shows an RGB image and a 3x3x3 filter moving through it with a defined step. The step is the value in pixels by which the filter moves. We can apply the “zero padding” option, i.e. filling with zeros (white squares). This procedure helps preserve more information at the expense of efficiency.
Subsequent values of the output matrix are calculated as follows:
multiplying the values in a given section of the image by the filter (after the elements),
summing up the calculated values for a given channel,
summing up the values for each channel taking into account the bias (in this case equal to 1).
It is worth noting that the filter values for a particular channel may differ. The task of the convolution layer, is to extract features such as edges, colours, gradients. Subsequent layers of the network – using what the previous layers have determined – can detect increasingly complex shapes. Much like the layers of an ordinary network, the convolution layer is followed by an activation layer (usually a ReLU function), introducing non-linearity into the network.
We can interpret the result of the convolution with each filter as an image. Many such images formed by convolution with multiple filters are multi-channel images. An RGB image is something very similar – it consists of 3 channels, one for each colour. The output of the convolution layer, however, does not consist of colours per se, but certain “colour-shapes” that each filter represents. This is also responsible for noise reduction. The most popular method is “max pooling”.
Typically multiple filters are used, so that the convolution layer increases the depth, i.e. the number of image channels.
Bonding layer
Another layer, called the bonding layer, has the task of reducing the remaining dimensions of the image (width and height), while retaining key information needed, e.g. for image classification.
Figure 3 Diagram of the merging operation
The merging operation is similar to the one applied in the convolution layer. A filter and step are defined. The subsequent values of the output matrix are the maximum value covered by the filter.
Together, these layers form a single layer of the convolutional network. Once the selected number of layers has been applied, the resulting matrix is “flattened out” to a single dimension. It means that the width and height dimensions are gradually replaced by a depth dimension. The result of the convolutional layers translates directly into the input to the next network layers, usually the standard fully connected ones (Dense Layers). This allows the algorithm to learn the non-linear relationships between the features determined by the convolution layers.
The last layer of the network is the Soft-Max layer. It makes it possible to obtain values for the probabilities of class membership (for example, the probability that there is a cat in the image). During training, these are compared with the desired classification result in the applied cost function. Then, through a back-propagation algorithm, the network adjusts its weights to minimise the error.
Convolutional neural networks are an important part of the machine learning development. They contribute to the progress of automation and help extend to human perceptual abilities. Their capabilities will continue to grow with the computing power of computers and the amount of available data.
Today’s world is characterised by constant technological progress. You hear about new products, services, methods and other things virtually every day. Moreover, they are often referred to as “innovative” as well. This term can also be applied to companies, and companies increasingly often call themselves “innovative”, too. In today’s article, we will take a look at what innovation means in a company and how to promote it.
What is innovation?
Innovation is defined as “a set of competencies of an organisation to continuously discover sources of new solutions, as well as to absorb them from outside and generate on one’s own, and to implement and diffuse them (make them commonplace)”. Put simply, it is the ability to generate new ideas; the desire to improve, to create something new, and then implement and commercialise these new solutions. Innovation manifests itself in thinking outside the box, seeking solutions and going beyond the daily routine.
Virtually everyone knows companies like Apple, Google and Microsoft. Undoubtedly, these companies have achieved enormous global success through their innovation. This shows that the world is open to innovation and the demand for it is increasing. This also means that companies that do not follow the path of innovation may lose their competitiveness and ultimately cease to exist in a few years’ time. So do companies that do not have a charismatic leader like Steve Jobs or capital equal to that of Google have a chance to become innovative? The answer is a resounding YES! This is since innovation is not a trait that only the chosen few can attain it is an attitude that anyone can develop.
Attitude is key
Some people are born innovators. They find it remarkably easy to come up with new ideas. But what about the people who spend hours coming up with anything new and the results of their efforts still leave much to be desired? Well, we have one piece of advice for them — attitude is key! Innovation is primarily a kind of attitude that you can develop. The most important thing about being innovative is having an open mind. This is the driving force behind innovation. You will not invent anything new by repeating the same activities every day and cutting yourself off from any contact with the outside world.
This is where another innovation-driving factor comes in, i.e. contact. A lot of ideas come from outside as a result of conversations with others. That is why it is so vital to spend time with people, as well as to talk to them, and get their opinions on various topics. This allows you to trigger something within yourself, which may result in new ideas and solutions. Therefore, if you want to create innovation in your company, you have to start by changing your mindset.
“Architects of Innovation”
A key role in driving innovation in a company is played by leaders, who were dubbed “innovation architects” in “Innovation as Usual”, a book by Thomas Wedell-Wedellsborg and Paddy Miller. The above authors believe that the leader’s primary task is to create a culture of innovation in the company, i.e. conditions in which creativity is inherent in the work of every employee, regardless of their position. Here, they point to a mistake often made, which is the desire to create something innovative at a moment’s notice. To that end, companies hold brainstorming sessions and send their staff off to workshops that are meant to help them come up with new ideas.
However, this often has the opposite effect. Employees return to a job where they repeat the same thing every day, which kills their creativity. This is why it is so important to develop a culture of innovation that drives innovation on a daily basis. Such culture can manifest itself in the way work is organised, as well as the development of new habits, practices and rituals to help trigger new ideas.
Yet another task facing managers is the ability to motivate and support their employees. Leaders should serve as guides for their teams, as well as be able to spark creativity and mobilise them to generate new ideas. To enable this, the book’s authors have proposed a set of “5+1 keystone behaviours”, which include focus, insight, modification, selection and diplomacy. All these behaviours should be supported by perseverance in introducing innovation on a daily basis. The introduction of the “5+1 keystone behaviour” model in a company has a significant impact on shaping an attitude of innovation among employees. This ensures that the creation of new ideas is not a one-off activity but rather a permanent part of the company’s system.
Innovation management
Innovation is becoming increasingly vital. Many companies now set up dedicated departments to handle their innovation activities. Therefore, the introduction of an innovation management process is a key step in creating an innovative company.
The figure below shows the four pillars that should comprise an innovation management process according to Instytut Innowacyjności Polska.
Figure 1 Pillars of the innovation management process according to Instytut Innowacyjności Polska
The first and most important pillar in innovation management is diagnosis. Diagnosis is construed as the determination of the company’s previous innovation level, as well as an analysis of its environment in terms of its ability to create innovation. A company may carry out an innovation diagnosis on its own or have an outside company carry out a so-called “innovation audit”.
In the second step, an organisational structure and processes need to be put in place to implement the process of generating innovative ideas in the company.
The next step is to come up with new ideas and manage the process of their implementation.
The final pillar of innovation management is determining how innovation is to be funded. Funding may be provided through both internal and external sources (grants, investors, etc.).
The innovation management process is a must for any company that wants to successfully implement innovation. It makes it possible to effectively supervise the implementation of innovations, measure the company’s innovation level and control the expenses incurred in this area. By introducing this process, the company demonstrates that it deems innovation a top priority.
Conclusions
Innovation is certainly an issue that is becoming increasingly important. The high level of computerisation and technological progress makes the demand for innovation ever greater. Therefore, to stay in the market, companies should follow the path of innovation and shape this trait within their structures. As “innovation architects”, leaders play a vital role in this process and are tasked with creating a company system that triggers creative ideas in employees every day. In addition, a leader should be a kind of guide who motivates his or her team to act creatively. Creating innovation in a company is therefore a continuous, day-to-day process. However, there are solutions that support process management, such asData Engineering. Utilising cutting-edge IoT technology to collect and analyse information, Data Engineering enables companies to make quick and accurate decisions.
IoT is a broad term, often defined in different ways. To get a good understanding of what the Internet of Things actually is, it’s best to break the term down into few parts.
What is referred to as a “Thing” in the Internet of Things are objects, animals and even people equipped with smart devices (sensors) to collect certain information. So that thing could be either a fridge that uses a smart module or an animal with a smart band applied to it that monitors its vital functions. Devices communicate to send and receive data. In order for them to communicate, they need a network connection, and this is referred to as the “Internet” in IoT. This connection can be made with a variety of data transmission technologies. We can mention Wi-Fi, 5G networks, Bluetooth, as well as more specialised protocols such as Zigbee, which, thanks to its low power consumption, is great for IoT devices where lifespan is of key importance, or Z-Wave often used in smart building systems.
It’s a good idea to mention here that not every IoT device needs to have direct access to the Internet. The data collected by IoT devices is then uploaded and analysed. In order to efficiently collect and analyse large data sets, as well as to ensure high system scalability, cloud technologies are often used. In this case, Internet of Things devices can send data to the cloud via an API ( (API gateway). This data is then processed by various software and analytical systems. Big Data, artificial intelligence and machine learning technologies are used to process data.
IoT applications
IoT has many various applications, using household items, lighting or biometric devices, to name a few.
Figure 1 Internet of Things
The figure above shows 101 terms related to the Internet of Things, divided into categories. It’s plain to see that there are many technologies associated with IoT, ranging from connectivity issues, data processing and analysis to security and IoT network architecture. We will not describe the above-mentioned technologies in this article, but we should bear in mind what an immensely extensive field IoT is and how many other technologies are involved.
The Internet of Things is developing at a very fast pace, recording high annual growth rates. According to various estimates, the IoT market will grow at a rate of 30 per cent in the next few years, and in Poland this rate could reach up to 40 per cent. By 2018, there were around 22 billion connected Internet of Things devices, and it is estimated that this number could be up to as many as 38.6 billion devices by 2025.
The Internet of Things in the future
The Internet of Things is finding its way into more and more areas of our lives. Household goods and lighting items are things we use pretty much every day. If we add some “Intelligence” to ordinary objects, it becomes easier to manage the entire ecosystem of our home or flat. As a result, we will be able to optimise the costs of equipment wear and tear and their working time. The collection of huge amounts of data, which will then be processed and analysed, is expected to bring about even better solutions in the future. In recent years, it’s often been mentioned that “Data is the gold of the 21st century.” and IoT is also used to collect this data. With IoT progressing like that, it won’t be long before smart devices are with us in the vast majority of our daily activities.
Controversy around the Internet of Things
The development of the Internet of Things will bring many changes to everyday life. The biggest problem with this is security. Because of the amount of data collected by devices, which very often have no or very low levels of security, exposes the user to breach or having no control over such data. Another issue is the dispute over who should have access to the data. Questions of morality are raised here, such as whether large corporations should be able to eavesdrop on the user on a daily basis. The companies explain their modus operandi by the fact that the data collected is a tool for the development of the offered services.
Opponents, on the other hand, see it the other way around, considering an intrusion into user privacy and uncertainty with where the collected data may end up. However, a new avenue is emerging, namely – the use of blockchain technology to securely store data in the IoT network. By using a decentralised blockchain network, there will be no central entity with control over user data. The technology also ensures the non-repudiation of the data, meaning the certainty that the data has not been modified by anyone.
Who will benefit form the Internet of Things?
IoT is targeting different industries. Solutions are being developed for both the consumer market and the business market. The companies involved in this area will have a substantial platform to develop their solutions. The upcoming revolution will also change many areas of our lives. Also, the ordinary user will also get something out it, as he or she will have access to many solutions that will make his or her life easier. The Internet of Things presents tremendous opportunities, but there is no denying that it can also bring entirely new risks. So – in theory – the IoT will benefit everyone. You can read more about the security of IoT devices in our article.
BFirst.Tech and IoT
As a company specialising in the new technology sector, we are not exactly sleeping on the subject of IoT either. Working with Vemmio, we are developing the design of a voice assistant to manage a house or flat in a Smart Home formula. Our solution will implement a voice assistant on the central control device of the Smart Home system. Find out more about our projects here.
With biometric authentication, the first thing that gets checked is the voice that issued the command to activate the device. If the voice authentication is positive, the device is ready to operate and issue commands through which home appliances can be managed. That’s exactly the idea behind the Smart Home. This solution makes it possible to manage a flat or smaller segments of it or even an entire building.
Individual household appliances, lighting or other things are configured with a device that helps us manage our farm. This is the technical side, where the equipment has to be compatible with the management device. This puts the control centre in one place, and today operating entire system can be managed with a smartphone is already a standard. With the voice assistant feature, the entire system can be controlled without having to physically use the app. Brewing coffee in the coffee machine, adjusting the lighting or selecting an energy-saving programme will be all possible with voice commands.
The topic of neural networks in the IT area has become very popular in recent years. Neural networks are not a new concept, as they were already popular in the 1970s. However, their real development took place in the 21st century due to the technology’s huge leap forward. Neural networks are one of the areas of artificial intelligence (AI). The interest in neural networks is growing, thus forcing us to constantly develop and improve them.
Characteristics
In order to describe the way neural networks work, it is worth referring (in a certain simplification) to the way the human nervous system works. The characteristic of the functionality is acting as a biological system. Despite enormous progress and the use of innovative solutions, today’s networks still are not able to act as well as the human brain. However, it can’t be ruled out that in the future such an advanced stage of development will be reached.
Neural network structure
The neural network consists of a certain number of neurons. The simplest neural network is called perceptone, which consists of only one artificial neuron. Input data with assigned weight scales are sent to the perceptone – it determines the final result of a parameter. This set of data is later sent to the summation block. The summation block is just a pattern, an algorithm prepared by programmers. Summing all inputs gives a result, which in today’s advanced types of artificial neurons answers the form of a real number. The result informs about the type of decision that was made based on the calculations.
Img 1 Schematic diagram of how a perceptron works. Each of the 4 input elements is multiplied by its corresponding weights. The products are summed (summation block) and the sum is passed to the activation function (activation block), whose output is also the output of the perceptron.
The usage of neural networks
When it comes to the development of AI, it is closely connected to the development of neural networks. An unquestionable advantage of networks is that they have a wide range of applications. Furthermore, they leave room for unlimited possibilities for further development. Another advantage of it is that they deal well with large data sets, which are sometimes very difficult for humans. What’s more, they can adapt to the new situations when new variables appear. However, most available on the market programs do not have this possibility.
Neural networks’ ability to work based on damaged data is still a field of development. They will find applications in a growing number of areas, mainly in finance, medicine, and technology. Neural networks will appear successively in areas that require solutions related to prediction, classification, and control. They will find their application wherever creating scenarios or making decisions is based on many variables.