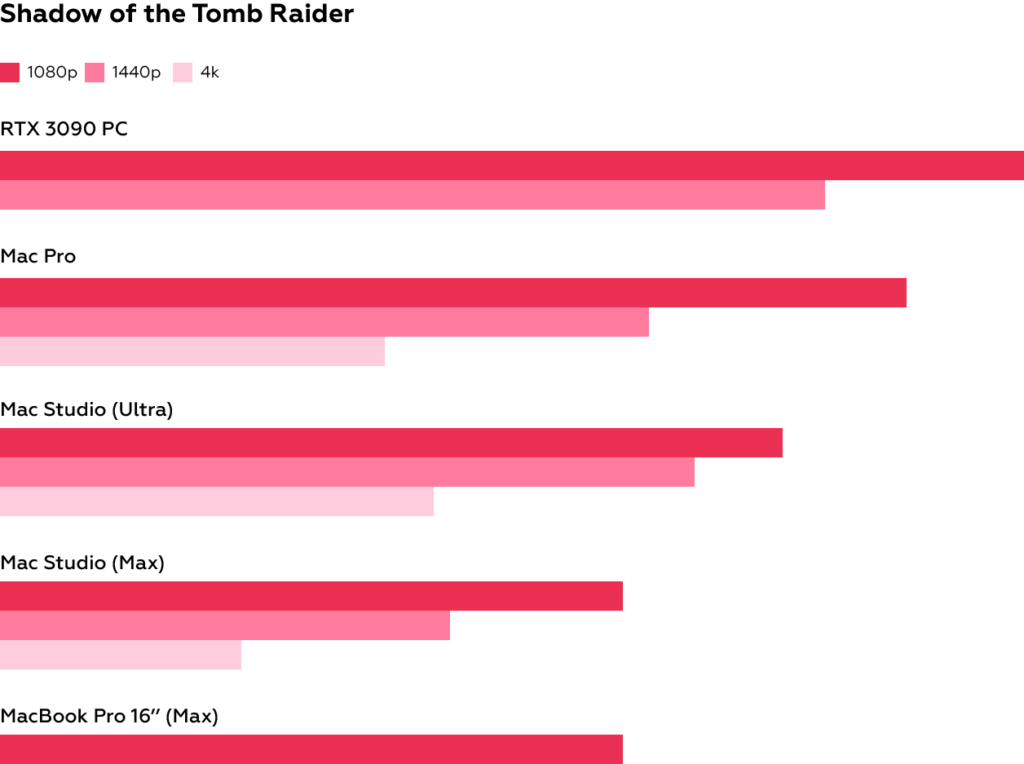Artificial intelligence and voice creativity
Artificial intelligence (AI) has recently ceased to be a catchphrase that belongs in science-fiction writing and has become part of our reality. From all kinds of assistants to text, image, and sound generators, the machine and the responses it produces have made their way into our everyday lives. Are there any drawbacks to this situation? If so, can they be counterbalanced by benefits? This post addresses these questions and other dilemmas related to the use of AI in areas involving the human voice.
How does artificial intelligence get its voice? The development of AI voices encompasses a number of cutting-edge areas, but the most commonly used methods include
- machine learning algorithms that allow systems to learn from data and improve their performance over time. Supervised learning is often employed to train AI voice models using large data sets related to human speech. With supervised learning, an AI model learns to recognise patterns and correlations between text input and corresponding voice messages. The AI learns from multiple examples of human speech and adjusts its settings so that the output it generates is as close as possible to real human speech. As the model processes more data, it refines its understanding of phonetics, intonation, and other speech characteristics, which results in increasingly natural and expressive voices;
- natural language processing (NLP) enables machines to understand and interpret human language. Applying NLP techniques allows artificial intelligence to break down written words and sentences to find important details such as grammar, meaning, and emotions. NLP allows AI voices to interpret and speak complex sentences, even if the words have multiple meanings or sound the same. Thanks to this, the AI voice sounds natural and makes sense, regardless of the type of language used. NLP is the magic that bridges the gap between written words and speech, making AI voices sound like real people, even when complex language patterns are involved.
- Speech synthesis techniques allow machines to transform processed text into intelligible and expressive speech. This can be done in a variety of ways, for example, by assembling recorded speech to form sentences (concatenative synthesis) or using mathematical models to create speech (parametric synthesis), which allows for greater customisation. Recently, a breakthrough method called neural TTS (Text-to-Speech) has emerged. It uses deep learning models, such as neural networks, to generate speech from text. This technique makes AI voices sound even more natural and expressive, capturing the finer details, such as rhythm and tone, that make human speech unique.
In practice, the available tools can be divided into two main categories: Text-to-Speech and Voice-to-Voice. Each allows you to clone a person’s voice, but TTS is much more limited when it comes to reproducing unusual words, noises, reactions, and expressing emotions. Voice-to-Voice, put simply, “replaces” the sound of one voice with another, making it possible, for example, to create an artificial performance of one singer’s song by a completely different singer, while Text-to-Speech uses the created voice model to read the input text (creating a spectrogram from the text and then passing it to a vocoder, which generates an audio file) [1]. As with any machine learning issue, the quality of the generated speech depends to a large extent on the model and the data on which the model was trained.
While the beginnings of the research on human speech can be traced back to as early as the late 18th century, work on speech synthesis gained momentum much later, in the 1920s-30s, when the first vocoder was developed at Bell Labs [2]. The issues related to voice imitation and cloning (which is also referred to as voice deepfakes) were first addressed on a wider scale in a scientific paper published in 1997, while the fastest development of the technologies we know today occurred after 2010. The specific event that fuelled the popularity and availability of voice cloning tools was Google’s publication of the Tacotron speech synthesis algorithm in 2017 [3].
Artificial intelligence can already “talk” to us in many daily life situations; virtual assistants like Siri or Alexa found in devices and customer service call machines encountered in various companies and institutions are already widespread. However, the technology offers opportunities that could cause problems, raising controversy about the ethics of developing it in the future.
At the forefront here are the problems raised by voice workers, who fear the prospect of losing their jobs to machines. For these people, apart from being part of their identity, their voice is also a means of artistic expression and a work tool. If a sufficiently accurate model of a person’s voice is created, then suddenly, at least in theory, that person’s work becomes redundant. This very topic was the subject of a discussion that ignited the Internet in August 2023, when a YouTube creator posted a self-made animation produced in Blender, inspired by the iconic TV series Scooby-Doo [4]. The controversy was caused by the application of AI by the novice author to generate dialogues for the four characters featured in the cartoon, using the voice models of the original cast (who were still professionally active). A wave of criticism fell on the artist for using someone else’s voice for his own purposes, without permission. The issue was discussed among animation professionals, and one of the voice actresses from the original cast of the series also commented on it. She expressed her outrage, adding that she would never work with this artist and that she would warn her colleagues in the industry against him. As the artist published an apology (admitting his mistake and explaining that his actions were motivated by the lack of funds to hire voice-overs and the entirely amateur and non-profit nature of the animation he had created), the decision to blacklist him was revoked and the parties reconciled. However, what emerged from the discussion was the acknowledgment that the use of artificial intelligence for such purposes needs to be legally regulated. The list of professions affected by this issue is long, and there are already plenty of works using people’s voices in a similar way. Even though this is mostly content created by and for fans paying a kind of tribute to the source material, technically speaking, it still involves using part of someone’s identity without their permission.
Another dilemma has to do with the ethical concerns that arise when someone considers using the voice of a deceased person to create new content. The Internet is already full of “covers” in which newly released songs are “performed” by deceased artists. This is an extremely sensitive topic, considering the feelings of the family, loved ones, and fans of the deceased person, as well as how the deceased person would feel knowing that part of their image was used this way.
Another danger is that the technology may be used for the purposes of deception and misrepresentation. While remakes featuring politicians playing multiplayer games remain in the realm of innocent jokes, putting words that the politicians have never said into their mouths, for example, during an election campaign, is already dangerous and can have serious consequences for society as a whole. Currently, the elderly are particularly vulnerable to such fakes and manipulation, however, with the improvement of models and the parallel development of methods for generating images and mouth movements, even those who are familiar with the phenomenon may find it increasingly difficult to tell the difference between what is false and what is real [5].
In the worst-case scenario, such deceptions can result in identity theft. From time to time, we learn about celebrities appearing in advertisements that they have never heard of [6]. Experts and authorities in specific fields, such as doctors, can also fall victim to this kind of identity theft when their artificially created image is used to advertise various preparations that often have nothing to do with medicine. Such situations, already occurring in our country [7], are particularly harmful, as potential recipients of such advertisements are not only exposed to needless expenses but also risk their health and potentially even their lives. Biometric verification by voice is also quite common. If a faithful model of a customer’s voice is created and there is a leak of his or her personal data, the consequences may be disastrous. The risk of such a scenario has already materialised for an application developed by the Australian government [8].
It is extremely difficult to predict in what direction the development of artificial intelligence will go with regard to human voice generation applications. It seems necessary to regulate the possibility of using celebrity voice models for commercial purposes and to ensure that humans are not completely replaced by machines in this sphere of activity. Failure to make significant changes in this matter could lead to a further loss of confidence in tools using artificial intelligence. This topic is divisive and has many supporters as well as opponents. Like any tool, it is neither good nor bad in itself – rather, it all depends on how it is used and on the user’s intentions. We already have tools that can detect whether a given recording has been artificially generated. We should also remember that it takes knowledge, skill, and effort to clone a human voice in a convincing way. Otherwise, the result is clumsy and one can immediately tell that something is not right. This experience is referred to as the uncanny valley. The subtleties, emotions, variations, accents, and imperfections present in the human voice are extremely difficult to reproduce. This gives us hope that machines will not replace human beings completely, and this is only due to our perfect imperfection.