W erze cyfryzacji rośnie zapotrzebowanie na zaawansowane technologie nie tylko do gromadzenia, ale przede wszystkim analizy danych. Przedsiębiorstwa akumulują coraz większe ilości różnorodnych informacji, które mogą zwiększać ich efektywność i innowacyjność. Produkt Data Engineering oferowany przez firmę BFirst.Tech może odgrywać kluczową rolą w procesie wykorzystywania tych danych dla dobra firmy. Jest to jedna z najnowocześniejszych technologii do efektywnego zarządzania i przetwarzania informacji. W niniejszym artykule przedstawimy jedną z możliwości oferowanych przez Jezioro Danych.
Data Engineering – najnowsza technologia do zbierania i analizowania informacji
Inżynieria danych to proces projektowania oraz wdrażania systemów do efektywnego zbierania, przechowywania i przetwarzania obszernych zbiorów danych. Wspiera to akumulację informacji, takich jak analiza ruchu na stronach internetowych, dane z czujników IoT, czy trendy zakupowe konsumentów. Zadaniem inżynierii danych jest zapewnienie, że informacje są zręcznie gromadzone i magazynowane oraz łatwo dostępne i gotowe do analizy. Dane mogą być efektywnie przechowywane w jeziorach, hurtowniach czy składnicach danych, a tak zintegrowane źródła danych mogą służyć do tworzenia analiz lub zasilania silników sztucznej inteligencji. Zapewnia to wszechstronne wykorzystanie zgromadzonych informacji (patrz szczegółowy opis produktu Data Engineering (rys. 1)).

rys. 1 – Data Engineering
Jezioro Danych w przechowywaniu zbiorów informacji
Jezioro Danych pozwala na przechowywanie ogromnych ilości surowych danych w ich pierwotnym, nieprzetworzonym formacie. Dzięki możliwościom, jakie oferuje Data Engineering, Jezioro Danych jest zdolne do przyjmowania i integracji danych z różnorodnych źródeł. Mogą to być dokumenty tekstowe, ale także obrazy, aż po dane pochodzące z czujników IoT. To umożliwia analizę i wykorzystanie złożonych zbiorów informacji w jednym miejscu. Elastyczność Jezior Danych oraz ich zdolność do integracji różnorodnych typów danych sprawiają, że stają się one niezwykle cenne dla organizacji, które stoją przed wyzwaniem zarządzania i analizowania dynamicznie zmieniających się zbiorów danych. W przeciwieństwie do hurtowni danych, Jezioro Danych oferuje większą wszechstronność w obsłudze różnorodnych typów danych. Jest to możliwe dzięki zaawansowanym technikom przetwarzania i zarządzania danymi stosowanym w inżynierii danych. Jednakże, ta wszechstronność rodzi również wyzwania w zakresie przechowywania i zarządzania tymi złożonymi zbiorami danych, wymagając od inżynierów danych ciągłego dostosowywania i innowacyjnych podejść. [1, 2]
Jezioro Danych a przetwarzanie informacji i wykorzystanie uczenia maszynowego
Rosnąca ilość przechowywanych danych oraz ich różnorodność stanowią wyzwanie w zakresie efektywnego przetwarzania i analizy. Tradycyjne metody często nie nadążają za tą rosnącą złożonością, prowadząc do opóźnień i ograniczeń w dostępie do kluczowych informacji. Uczenie maszynowe, wsparte przez innowacje w dziedzinie inżynierii danych, może znacząco usprawnić te procesy. Wykorzystując obszerne zbiory danych, algorytmy uczenia maszynowego identyfikują wzorce, przewidują wyniki i automatyzują decyzje. Dzięki integracji z Jeziorami Danych (rys. 2), mogą one pracować z różnymi typami danych, od strukturalnych po niestrukturalne, umożliwiając przeprowadzanie bardziej złożonych analiz. Ta wszechstronność pozwala na głębsze zrozumienie i wykorzystanie danych, które byłyby inaczej niedostępne w tradycyjnych systemach.
Zastosowanie uczenia maszynowego w Jeziorach Danych umożliwia głębszą analizę i efektywniejsze przetwarzanie dzięki zaawansowanym narzędziom i strategiom inżynierii danych. Pozwala to organizacjom transformować ogromne ilości surowych danych w użyteczne i wartościowe informacje. Jest to istotne dla zwiększenia ich efektywności operacyjnej i strategicznej. Ponadto, wykorzystanie uczenia maszynowego wspomaga interpretację zgromadzonych danych i przyczynia się do bardziej świadomego podejmowania decyzji biznesowych. W efekcie, firmy mogą dynamiczniej dostosowywać się do rynkowych wymogów i innowacyjnie tworzyć strategie oparte na danych.

rys. 2 – Jezioro Danych
Podstawy uczenia maszynowego oraz kluczowe techniki i ich zastosowania
Uczenie maszynowe, będące integralną częścią tzw. sztucznej inteligencji, umożliwia systemom informatycznym samodzielne uczenie się i doskonalenie na podstawie danych. W tej dziedzinie wyróżniamy typy uczenia takie jak uczenie nadzorowane, uczenie nienadzorowane i uczenie ze wzmocnieniem. W uczeniu nadzorowanym każdy przykład danych ma przypisaną etykietę lub wynik, który pozwala maszynom na naukę rozpoznawania wzorców i przewidywania. Stosowane jest to m.in. w klasyfikacji obrazów lub prognozowaniu finansowym. Z kolei uczenie nienadzorowane, pracujące na danych bez etykiet, skupia się na znajdowaniu ukrytych wzorców. Jest to użyteczne w zadaniach takich jak grupowanie elementów czy wykrywanie anomalii. Natomiast uczenie ze wzmocnieniem opiera się na systemie nagród i kar, pomagając maszynom optymalizować swoje działania w dynamicznie zmieniających się warunkach, jak np. w grach czy automatyce. [3]
Co jeśli chodzi o algorytmy? Sieci neuronowe są doskonałe do rozpoznawania wzorców skomplikowanych danych – jak obrazy czy dźwięk – i stanowią podstawę wielu zaawansowanych systemów AI. Drzewa decyzyjne są używane do klasyfikacji i analizy predykcyjnej, na przykład w systemach rekomendacji lub prognozowaniu sprzedaży. Każdy z tych algorytmów ma swoje unikalne zastosowania. Może być dostosowany do specyficznych potrzeb zadania lub problemu, co czyni uczenie maszynowe wszechstronnym narzędziem w świecie danych.
Przykłady zastosowań uczenia maszynowego
Zastosowanie uczenia maszynowego w Jeziorach Danych, otwiera szerokie spektrum możliwości, od detekcji anomalii po personalizację ofert i optymalizację łańcuchów dostaw. W sektorze finansowym algorytmy te skutecznie analizują wzorce transakcji, identyfikując nieprawidłowości i potencjalne oszustwa w czasie rzeczywistym, co ma kluczowe znaczenie w zapobieganiu oszustwom finansowym. W handlu detalicznym i marketingu, uczenie maszynowe pozwala na personalizację ofert dla klientów poprzez analizę zachowań zakupowych i preferencji, zwiększając satysfakcję klienta i efektywność sprzedaży. [4] W przemyśle, algorytmy te przyczyniają się do optymalizacji łańcuchów dostaw, analizując dane z różnych źródeł, jak prognozy pogody czy trendy rynkowe, co pomaga w przewidywaniu popytu i zarządzaniu zapasami oraz logistyką [5].
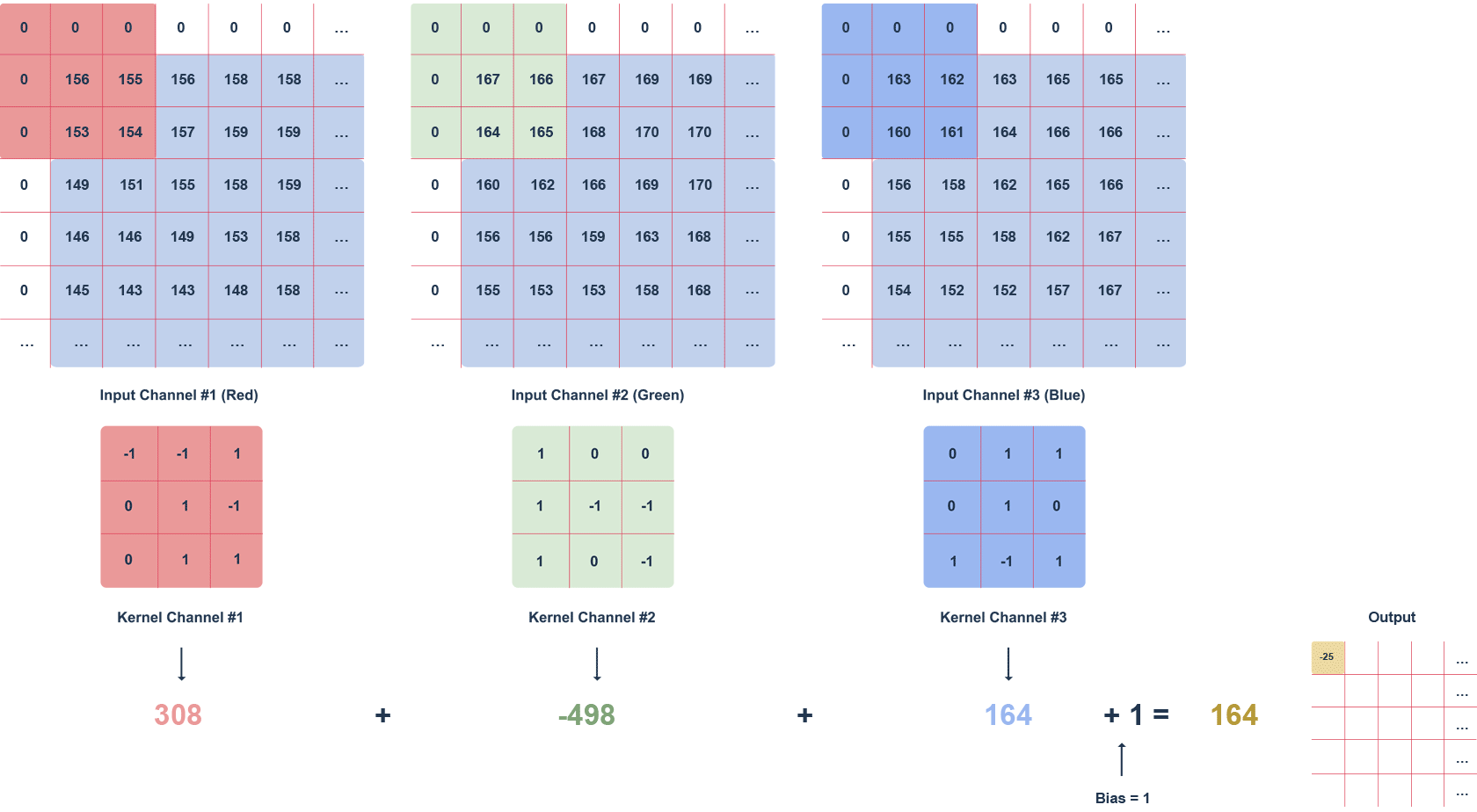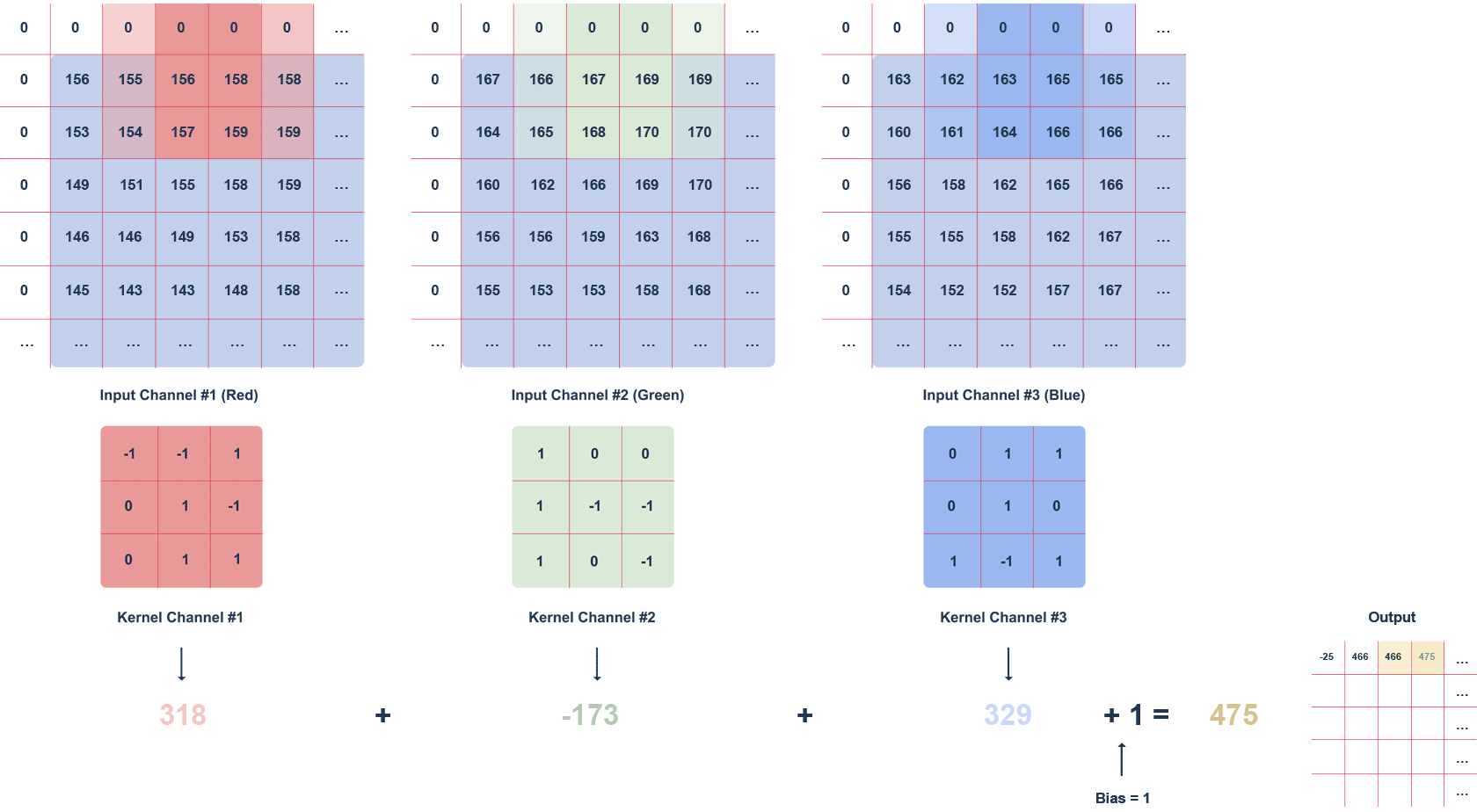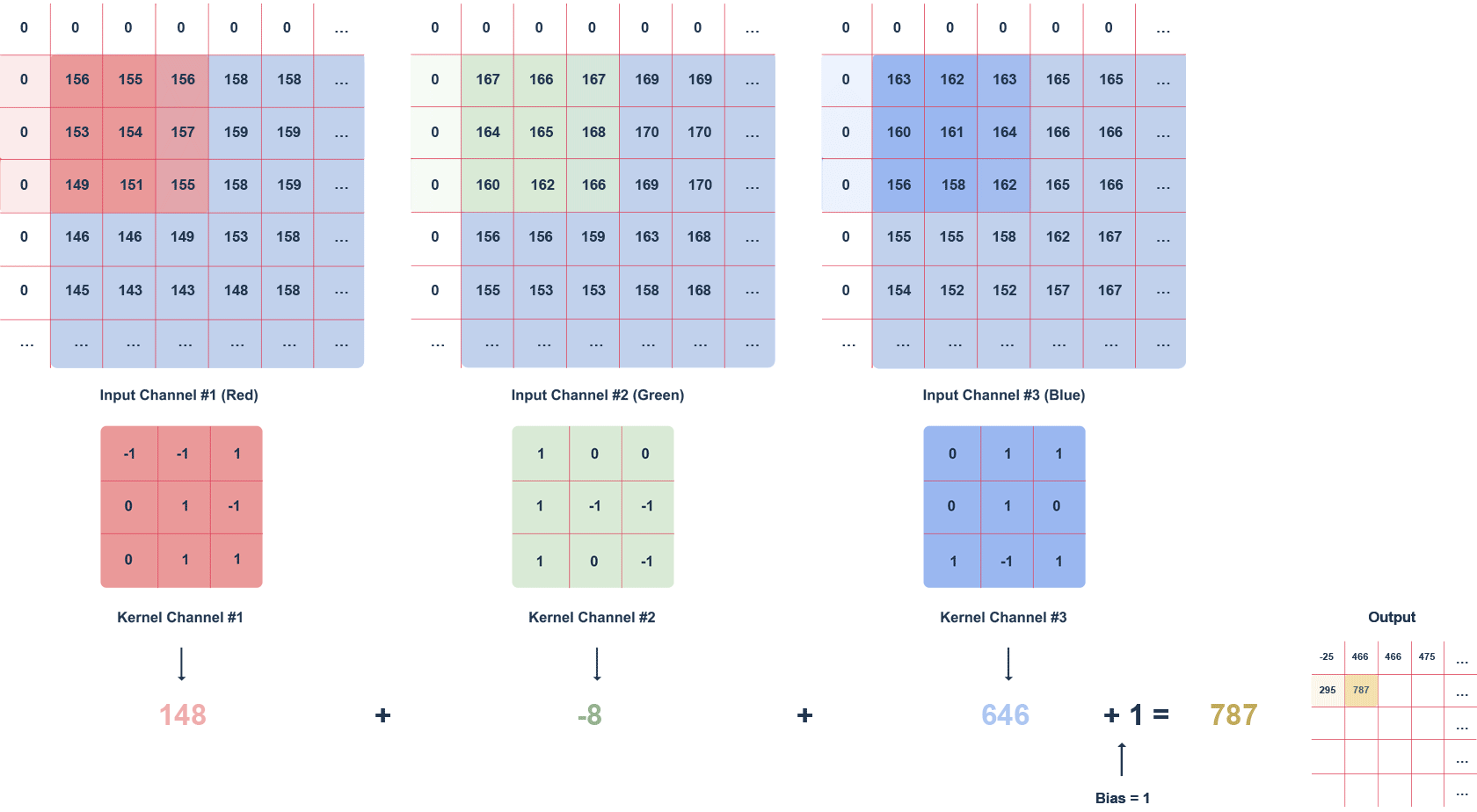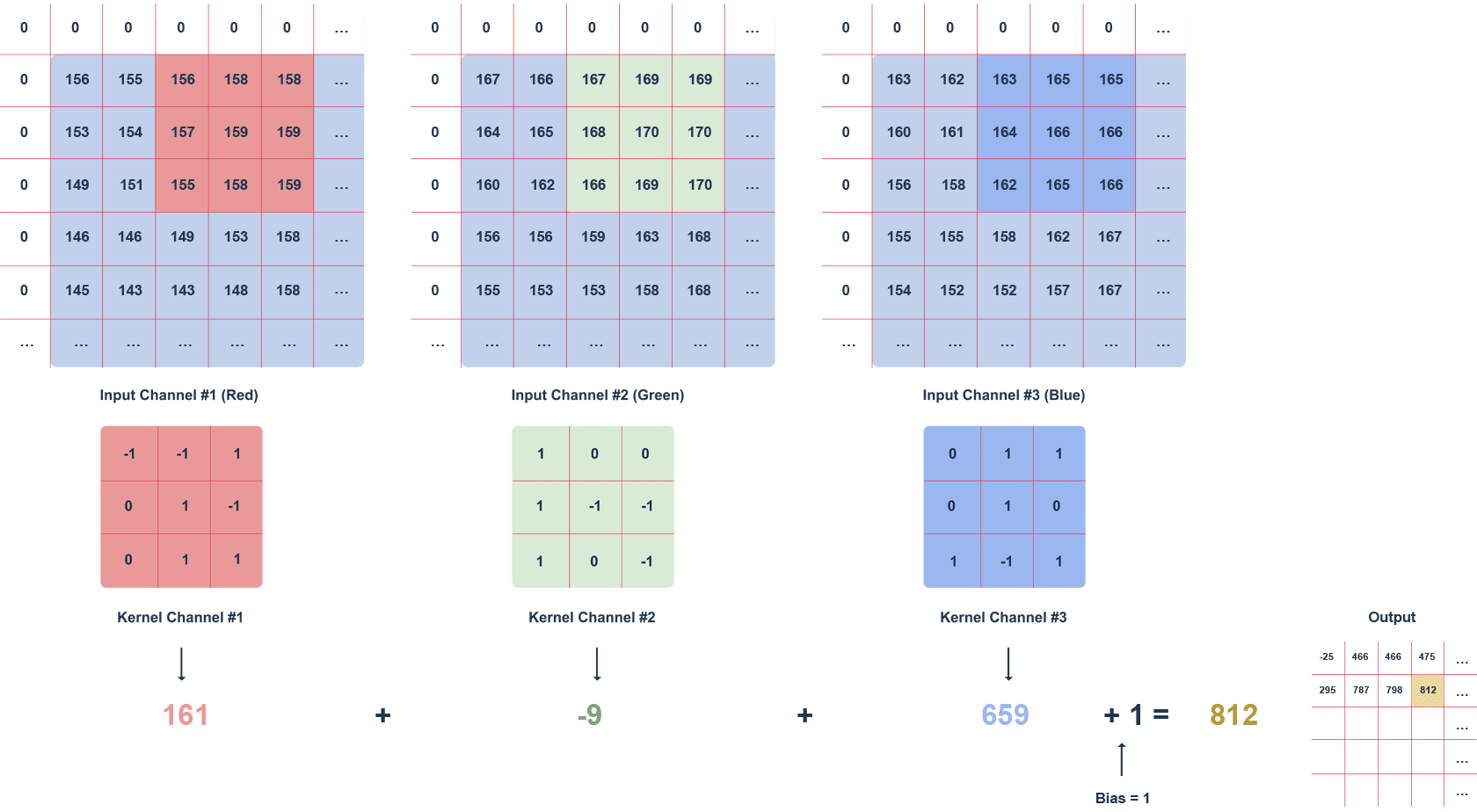
Można je też wykorzystać do wstępnego projektowania czy optymalizacji produktów. Innym, interesującym zastosowaniem uczenia maszynowego w Jeziorach Danych jest analiza obrazów. Algorytmy uczenia maszynowego są w stanie przetwarzać i analizować duże zbiory zdjęć czy obrazów, znajdując zastosowanie w takich dziedzinach jak diagnostyka medyczna, gdzie mogą pomagać w wykrywaniu i klasyfikowaniu zmian chorobowych na obrazach radiologicznych, czy w systemach bezpieczeństwa, gdzie analiza obrazu z kamer może służyć do identyfikacji i śledzenia obiektów lub osób.
Podsumowanie
Artykuł ten zwraca uwagę na rozwój w obszarze analizy danych, podkreślając jak uczenie maszynowe, Jeziora Danych i inżynieria danych wpływają na sposób w jaki organizacje przetwarzają i wykorzystują informacje. Wprowadzenie tych technologii do biznesu ulepsza istniejące procesy oraz otwiera drogę do nowych możliwości. Data Engineering wprowadza modernizację w przetwarzaniu informacji, która charakteryzuje się większą precyzją, głębszymi wnioskami i bardziej dynamicznym podejmowaniem decyzji. To podkreśla rosnącą wartość inżynierii danych w nowoczesnym świecie biznesu, co jest ważnym czynnikiem w dostosowywaniu się do zmieniających się wymagań rynkowych i tworzeniu strategii opartych na danych.
Bibliografia
[1] https://bfirst.tech/data-engineering/
[2] https://www.netsuite.com/portal/resource/articles/data-warehouse/data-lake.shtml
[3] https://mitsloan.mit.edu/ideas-made-to-matter/machine-learning-explained
[4] https://www.tableau.com/learn/articles/machine-learning-examples